deepseek识图功能什么时候上线?这一备受关注的问题,今天就上线了!2026年4月29日DeepSeek多模态团队负责人陈小康在X平台发布一条动态,仅用一句「Now,we see you.」,便向外界释放了多模态功能落地的信号。
一、deepseek识图功能
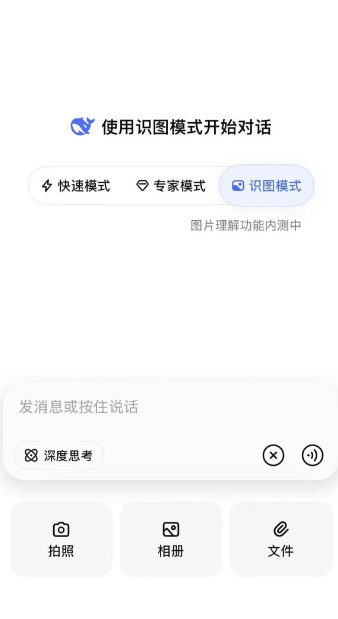
几乎在同一时间,部分用户在DeepSeek官方App中,意外发现了一个灰度测试新入口。在原有「快速模式」「专家模式」的基础上,输入栏上方新增「识图模式」选项,旁边清晰标注着「图片理解功能内测中」,意味着该功能已进入小范围试运营阶段。
公开资料显示,陈小康作为DeepSeek多模态方向的核心研究员,目前核心工作聚焦于多模态大语言模型的研究与开发。其教育背景十分扎实,本科与博士阶段均就读于北京大学,博士期间师从曾刚教授,技术根基始于计算机视觉领域,研究范围广泛,涵盖语义分割、目标检测、自监督学习、masked image modeling,以及后续的多模态理解与生成统一模型。
早期阶段,陈小康曾参与CPS半监督语义分割、CAE视觉自监督预训练等重要项目,凭借深厚的技术积累,在CVPR、ICCV、ECCV、IJCV等国际顶会及核心期刊上发表多篇学术论文。加入DeepSeek后,他将工作重心转向多模态基础模型的研发,成为公司多模态能力建设的核心力量,先后参与或主导Janus系列、DeepSeek-VL2等重点项目,其中Janus系列尤为注重视觉理解与图像生成能力的一体化打造。
从灰度测试的实际体验来看,用户上传图片后,DeepSeek会先精准捕捉用户核心需求,再对图片内容进行全面解析,最终输出结构化的描述内容。这也是DeepSeek主线产品中,首次引入图像理解能力,填补了此前在视觉领域的空白。
过去一年,DeepSeek的产品标签始终清晰明确,低成本训练、MoE架构、超强推理能力、出色代码能力以及完善的开源生态,构成了其核心竞争力。无论是此前的V3、R1版本,还是近期刚刚发布的V4系列,其核心发力点始终集中在文本模型领域,在纯文本交互场景中表现突出。
但当前大模型行业的竞争,早已突破纯文本的局限。大模型要真正融入Agent、办公、编程、设计、浏览器等各类真实工作流,首要前提便是具备「看见」的能力——看懂截图、网页内容、程序报错、各类图表、合同扫描件以及手机界面,这些都是其落地应用的基础。
换而言之,多模态能力并非可有可无的附加功能,而是决定Agent能否真正实现高效工作、落地实用场景的关键前提,没有多模态支撑,Agent便难以衔接真实工作中的各类视觉需求。
二、deepseekV4的发布,是留下了一个明显的能力缺口?
识图模式的灰度上线,时间点尤为微妙。就在5天前,DeepSeek刚刚推出V4系列预览版,其中V4-Pro参数规模达到1.6T,V4-Flash则为284B,两款模型均支持100万token上下文,性能表现备受关注。官方也明确说明,App中的「专家模式」对应V4-Pro,「快速模式」则匹配V4-Flash。
但遗憾的是,V4系列依旧是纯文本模型,这与此前外界广泛流传的「V4将原生支持多模态」的传闻严重不符。从V4技术报告中也能看出,「将多模态能力融入模型体系」仅被列入未来发展方向,并未成为本次发布的核心内容。
也正因此,V4发布后,不少用户和行业人士纷纷疑惑:DeepSeek的多模态能力,到底何时才能落地?如今,这个问题终于有了部分答案。
从目前流出的灰度测试截图来看,此次上线的识图模式,更侧重于图像理解,而非原生多模态生成。它能够实现看图、解析图片内容、回应图片相关问题等基础功能,但暂时还未显现出图像生成、视频理解,或是更复杂的跨模态生成能力。
行业内较为合理的判断是,DeepSeek此次并未对V4主干模型进行重构,而是在其之外额外接入了一个视觉理解模块,以此快速让模型具备「看见」的基础能力,完成多模态布局的初步落地。
回顾过往,DeepSeek的成功核心,在于以极高的工程效率,打造出性能强劲的文本模型,在纯文本赛道站稳了脚跟。但进入2026年,大模型行业的竞争已升级为一场复杂的「体系战」,文本厚度、视觉入口、长上下文能力、Agent工具链、国产算力适配,乃至API生态与资本杠杆,每一个环节都成为影响企业竞争力、决定估值溢价的关键因素,单一的文本优势已难以支撑长期发展。