5月26日消息,微软研究院近期开源的 SkillOpt 框架(arXiv:2605.23904),把 Agent Skill 优化从"靠人写、一把生成、模型自我重写"这种近似手工艺的状态,推到了"和神经网络训练同等纪律"的工程化路径。论文核心数据:在 6 个 benchmark、7 个目标模型、3 种 execution harness 的 52 项组合中,SkillOpt 全部取得最佳或并列最佳,在 GPT-5.5 上把无 skill 基线在 Direct Chat 抬升 23.5 分、Codex 抬升 24.8 分、Claude Code 抬升 19.1 分。GitHub 仓库 microsoft/SkillOpt 与项目页 microsoft.github.io/SkillOpt 同步开放,论文作者团队由 Yifan Yang、Dongdong Chen、Chong Luo 等 15 名微软研究员组成。 SkillOpt 是什么:把 Skill 当作冻结 Agent 的可训练外部状态
SkillOpt 的核心论点直接挑战了当前主流的 LLM 适配范式。微调要动权重、prompt 工程缺纪律、Claude Skills/Codex Skills 这类外部技能文件目前主要靠人工撰写或一次性 LLM 生成,论文作者认为这三者都不是真正的"训练"——没有反向传播,没有 learning rate,没有验证集 gate,无法在反馈下可重复地优于起点。
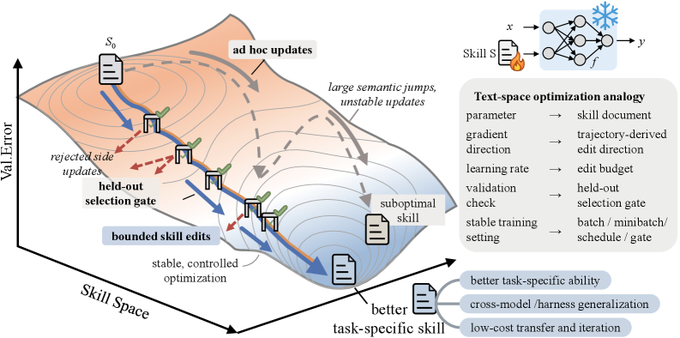
SkillOpt 的解决路径是:把 skill 文档本身当作冻结 agent 的外部状态(external state),给它一整套与权重空间优化对等的训练机制。目标模型(GPT-5.5、Qwen3.5-4B 等)、推理后端、执行 harness 都保持不动,真正被"训练"的只有一份 300-2000 token 的 best_skill.md 文档。
这套思路在概念上把 LLM 适配从两条传统路径——参数适配(SFT/LoRA/RLHF)、prompt 适配(GEPA/TextGrad 等)——切到了第三条:procedural adaptation,即过程性知识在自然语言层面的可控演化。
核心循环:Rollout → Reflect → Edit → Gate
SkillOpt 训练循环与神经网络训练有清晰的逐项对应:
Rollout(前向传播):冻结的目标模型用当前 skill 执行任务,记录消息、tool call、verifier 反馈、任务元数据与最终评分。
Reflect(语言层反向传播):一个独立的 optimizer model(论文典型设置是 GPT-5.5)分别处理失败与成功 minibatch,分析复用性 procedure 与重复性错误。
Edit(参数更新):Optimizer 提出结构化的 add / delete / replace 三类编辑提案,在一个 textual learning rate budget 之下汇总与排序。这一 budget 充当文本空间的学习率,防止单步对 skill 的大幅重写抹掉已经有效的规则。
Gate(验证集筛选):候选 skill 在 held-out selection split 上评测,只有严格优于当前 best 才会被接受,否则进 rejected-edit buffer 作为负反馈。每个 epoch 末还有 slow update 与 meta skill 两层长程更新,处理跨 epoch 的系统性规律。
整个过程的"参数"自始至终都是一份 .md 文件——部署阶段只需要把 best_skill.md 喂给冻结的目标模型,不需要 optimizer 介入,因此推理时延零额外开销。
Benchmark 领先:52/52 全部 SOTA,SpreadsheetBench 单项 +58.3
主结果表覆盖 SearchQA、Sheet(SpreadsheetBench)、Office、DocVQA、LiveMath、ALFWorld 六个 benchmark,跨 GPT-5.5、GPT-5.4、GPT-5.4-mini、GPT-5.4-nano、GPT-5.2、Qwen3.5-4B、Qwen3.6-35B-A3B 七个目标模型。关键数据点:
- GPT-5.5 Direct Chat:六项平均 +23.5 分,其中 Sheet +38.9、Office +39.0、LiveMath +29.3。
- GPT-5.5 Codex agentic loop:平均 +21.8,Sheet 单项 +57.5,LiveMath +28.0。
- GPT-5.5 Claude Code:平均 +18.6,Sheet 单项 +58.3。
- GPT-5.4-nano:平均 +24.9,其中 DocVQA +49.4、ALFWorld +35.1,显示小模型受益最大。
- Qwen3.5-4B:ALFWorld +50.7,跨家族适配同样有效。
单 case 走查:ALFWorld 一个典型 run 上,Selection Gate 分数从基线 68.6% 升到 81.4%,最终测试集 Hard 分从 70.9% 升到 85.8%;SpreadsheetBench 一个 run 上,held-out test 从 40.4 升到 78.9。
在所有 52 个(model, benchmark, harness)cell 中,SkillOpt 全部胜出或并列第一,完全压过 Trace2Skill、TextGrad、GEPA、EvoSkill 以及人工撰写、one-shot LLM 生成两类基线。这是目前 agent skill optimization 领域已发表工作中最完整的横向对比。
Ablation:learning rate、rejected buffer、slow update 三件套缺一不可
论文给出的 ablation 数据非常清晰地验证了每个组件的必要性,以 SearchQA / SpreadsheetBench / LiveMath 三项为例:
- 关掉 textual learning rate(lr=4 → 无 lr 约束):Spreadsheet 77.5→75.7,LiveMath 61.3→57.3。无约束下 optimizer 容易做大改动覆盖已经有效的规则。
- 关掉 rejected-edit buffer:Spreadsheet 77.5→72.9。失败编辑不留作负反馈,optimizer 反复踩坑。
- 同时关掉 slow update + meta skill:Spreadsheet 77.5→55.0,跌幅 22.5 分,这是所有 ablation 中最大的回撤,说明 epoch 级长程信号对稳定性至关重要。
三组数据共同指向同一个判断:把 skill 训成"参数"这件事,只有当 update 是 bounded、gated、buffered 的时候才真正稳定。这也是 SkillOpt 与既往"自我反思类"工作的本质分界。
迁移性:Cross-harness +31.8,Codex 训出的 skill 可直接搬到 Claude Code
best_skill.md 的可迁移性是 SkillOpt 的另一个关键卖点,三类迁移实验都给出正向结论:
- Cross-model:GPT-5.4 上训出的 LiveMath skill 直接迁到 GPT-5.4-nano,在 LiveMathBench 上比 nano 自身基线 +15.2 分。
- Cross-harness:在 Codex 上训出的 SpreadsheetBench skill,直接搬到 Claude Code 执行,比 Claude Code 自身基线 +31.8 分。
- Self-optimizer:GPT-5.4-nano 作为自己的 optimizer,也能让 SpreadsheetBench 提升 10.4 分——证明 SkillOpt 不仅是"从更强模型蒸馏过来"。
这一性质对企业用户的实际价值很高:可以在贵的优化器(GPT-5.5)上一次性训出 skill 文件,然后部署到便宜的目标模型与不同 agent harness,几乎不需要重新优化。
竞品对比:为什么 TextGrad、GEPA、EvoSkill 都没做到
- TextGrad:把整个 prompt 当 differentiable variable 做"文本梯度"更新,但没有验证集 gate 机制,容易越优化越散。
- GEPA:基于群体进化的 prompt/skill 搜索,缺 bounded update 控制,搜索成本高。
- EvoSkill:自我修订式 skill 演化,缺 rejected-edit buffer 与 slow update,无法稳定收敛。
- Trace2Skill / 人工 / one-shot LLM:本质都是"一次性生成 skill",不存在反馈回路。
SkillOpt 真正的方法论贡献是把"propose-and-test"这种 deep learning 工程标配纪律——bounded update、validation gate、negative feedback buffer、long-horizon memory——完整搬到自然语言层。
选型建议与上手路径
对工程团队,以下三类场景的判断已经较为清晰:
场景一:Claude Code / Codex 等 agentic harness 下的垂直能力优化——这是 SkillOpt 最契合的场景。已有 .md 体系的团队几乎可以无缝接入,把 SkillOpt 跑出来的 best_skill.md 直接替换或合并到现有 SKILL.md,即可看到显著提升。论文里 Codex / Claude Code 两条 harness 的 +21.8 与 +18.6 平均分,正是为这类用户准备的。
场景二:做 small model 部署 + 强 optimizer 训练 skill——典型组合是用 GPT-5.5 做 optimizer 训 skill,部署时用 GPT-5.4-nano 或 Qwen3.5-4B,享受 cross-model transfer 带来的成本/性能比。
场景三:闭源 API + 不能动权重的合规场景——SkillOpt 不需要任何 fine-tuning 权限,只通过 API 调用即可完成训练与部署,适合金融、医疗、法律等无法获取模型权重但需要垂直适配的环境。
不适合的场景同样需要明确。SkillOpt 需要一个可量化打分的 benchmark / verifier,对完全开放、没有客观评分的生成任务(创意写作、长篇报告)收敛性不可控;同时需要一个比目标模型更强的 optimizer,或至少等强(self-optimizer 模式),完全没有强 optimizer 可调用的团队需先解决这一前提。
上手路径低:git clone microsoft/SkillOpt → pip install -e . → 配置 Azure OpenAI endpoint → 准备 train/val/test 三 split → 一条命令启动 run。仓库提供 ALFWorld 完整 benchmark 安装脚本,以及 SpreadsheetBench、SearchQA 等多个评测域的现成 recipe,断点续跑也直接支持。对 Claude Skills / Codex Skills 体系下的实践者,SkillOpt 大概率会成为接下来一段时间内 SKILL.md 文件优化的事实标准工具链之一。