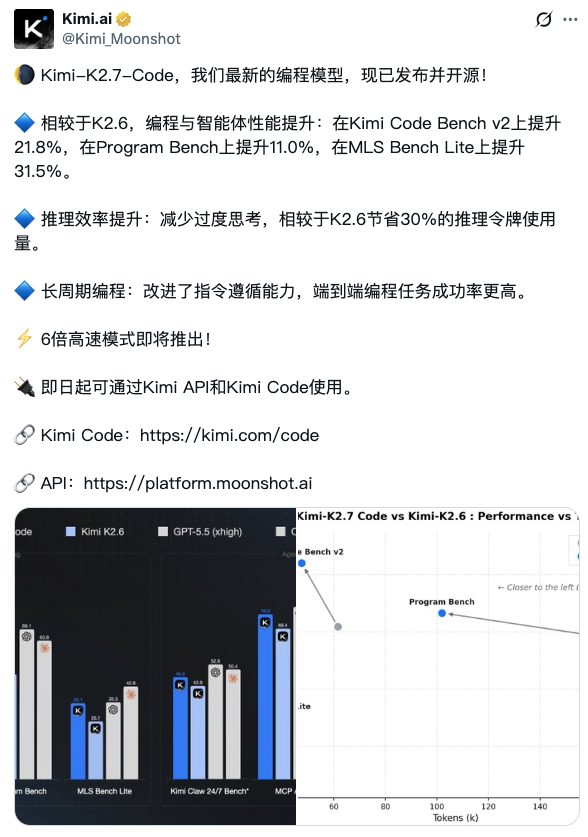
6月12日消息,月之暗面正式发布并开源Kimi K2.7 Code编程模型。官方公布的数据显示,相较于K2.6,K2.7 Code在Kimi Code Bench v2上提升21.8%,Program Bench上提升11.0%,MLS Bench Lite上提升31.5%,同时推理token消耗减少30%。模型即日起通过Kimi API和Kimi Code编程助手向所有用户开放,6倍高速模式即将推出。
三组基准数据拆解——K2.7改了什么
K2.7 Code公布了三项基准测试的提升幅度,每一项指向不同的能力维度。
Kimi Code Bench v2提升21.8%。这是月之暗面自建的编码基准,侧重评估在Kimi Code终端环境中的实际编程表现。21.8%的涨幅说明K2.7在"终端Agent式编码"这个月之暗面最核心的产品场景中有实质性改进。
Program Bench提升11.0%。相较于另外两项,这个涨幅偏保守,可能反映的是通用编程任务(非Agent式、非长程)的能力增量——K2.7的优化重心不在单次代码补全,而在端到端任务完成。
MLS Bench Lite提升31.5%,这是三项中涨幅最大的。MLS(Multi-step Long-range Software)测试评估的是多步骤、长周期软件工程任务的完成能力——正是K2.6发布时重点强调的"连续编码13小时+4000行代码"方向的延续。31.5%的跳升说明K2.7在长程任务上做了最大力度的优化。
一个同样重要的改进藏在性能数字之外:推理token消耗减少30%。官方表述是"减少过度思考"(reduced overthinking)。这直接回应了K2.6的一个已知问题——thinking模式下模型倾向于生成过长的推理链,在简单任务上浪费算力和时间。30%的token节省意味着对API调用方来说,同样的编程任务成本降低近三成,对Kimi Code用户来说,响应速度会有明显提升。
从K2.5到K2.7——5个月3个大版本的节奏
把K2.7放进月之暗面的迭代时间线上:K2.5在1月发布并开源(万亿参数MoE架构,引发Cursor"套壳"争议,SWE-Bench Verified 76.8%);K2.6在4月发布并开源(长程编码13小时/4000+行代码,300个子Agent集群调度,Terminal-Bench 2.0得分66.7,SWE-Bench Pro 58.6,对标GPT-5.4和Claude Opus 4.6)。
K2.7 Code在6月发布并开源,距K2.6约7-8周。月之暗面保持了每2-3个月一次大版本更新的节奏,但K2.7的发布策略有一个微妙变化:这次直接发布的是"K2.7 Code"而非通用版K2.7,且公布的全部基准都围绕编码场景。这说明K2.7可能不是一个全面升级的通用版本,而是专门针对Kimi Code产品线的编码能力迭代——月之暗面在编程Agent赛道上的投注越来越重。
另一个值得注意的信号:官方预告"6倍高速模式即将推出"。如果这指的是推理速度而非API限流,意味着月之暗面在推理优化上可能做了量化或蒸馏层面的工作,这将直接影响Kimi Code作为终端编程工具的交互体验——编程Agent的用户对延迟极其敏感。
此前Reddit社区有传闻称月之暗面在研发K3(目标3-4万亿参数)。K2.7 Code的出现说明在冲刺K3之前,月之暗面仍在通过".x"版本对K2系列的编码能力做快速打补丁——这和OpenAI在GPT-4到GPT-5之间密集推出中间版本的策略一脉相承。
竞品对比——编程Agent赛道的token经济性之争
K2.7 Code"推理token省30%"这个数据值得单独拿出来看,因为它指向的是编程Agent赛道当前最关键的竞争维度之一:token经济性。
Anthropic的Claude Code在终端编程Agent品类中拥有最强的品牌认知,但Claude Opus系列的推理成本一直是开发者的痛点——复杂编程任务动辄消耗数十万token,API账单极高。OpenAI的Codex走异步Agent路线,通过后台排队执行降低单次成本,但牺牲了实时交互体验。 月之暗面的策略是从两个方向同时压缩成本:一是开源(K2.5、K2.6、K2.7均开源,允许企业在自有GPU上运行,彻底回避API定价问题);二是减少过度思考(K2.7的30% token节省直接降低了API模式下的使用成本)。
如果"6倍高速模式"兑现,Kimi Code可能在"开源+低成本+快响应"这个组合上建立起与Claude Code和Codex都不同的差异化位置。不过需要提醒的是,K2.6发布时曾出现上线功能异常、被迫全员额度重置补偿的情况——大规模用户涌入后的稳定性,仍然是月之暗面需要反复证明的。
三个待观察问题
基准数字的含金量。 K2.7 Code公布的三项基准中,Kimi Code Bench v2和MLS Bench Lite是月之暗面内部基准,Program Bench也非行业通用标准。相比K2.6发布时同时公布SWE-Bench Pro、Terminal-Bench 2.0、DeepSearchQA等行业公认基准的做法,K2.7 Code这次的数据说服力要弱一些。如果后续没有第三方独立评测(如Vercel、Factory.ai等合作伙伴的验证数据),开发者社区的采信度可能有限。
K2.7通用版是否存在。 K2.6走过"Code Preview→通用版正式发布"的路径。K2.7目前只有Code版本,且全部基准都围绕编码——它究竟是K2系列的下一个完整版本,还是K2.6的编码增强补丁?这影响社区对K2.7在通用任务上能力的预期。
开源后的社区反应。 K2.5开源时引发了Cursor"套壳"争议,K2.6开源后在ModelScope和HuggingFace上的下载和fork数据表现不错。K2.7 Code如果只是编码方向的增量优化,社区关注度可能不如K2.6。但如果"减少30%推理token"的优化是架构层面的改进而非仅限于编码场景,那么这项技术在通用模型上的迁移价值可能被低估。