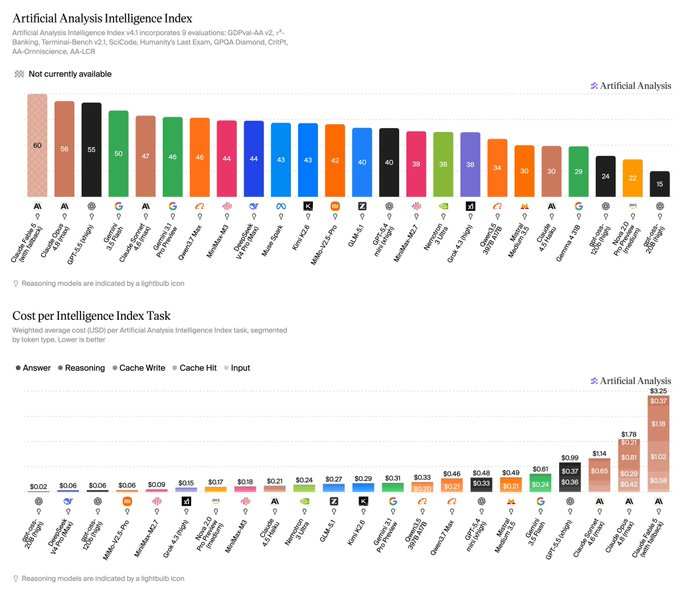
6月16日消息,AI基准测试机构Artificial Analysis发布智能指数(Intelligence Index)v4.1版本,从v4.0的10项评估缩减至9项,核心变化是升级三项智能体任务基准并移除一项已饱和的测试,同时首次引入每任务成本、每任务时间和每任务Token数三项效率指标。这次更新使该指数从"模型有多聪明"扩展到"聪明到这个程度要花多少钱和时间"。
方法论变更:三项升级,一项移除
v4.1对评估组成做了四处调整。Terminal-Bench Hard升级为Terminal-Bench v2.1,τ²-Bench Telecom升级为τ³-Bench Banking——两者均采用更新的任务集,包含更困难和更贴近真实场景的智能体任务,目的是拉开前沿模型之间的区分度。GDPval-AA升级为v2版本,将Elo基准重新校准至人类表现水平(1000分),引入轮换制的前沿模型评审小组,并将对话轮次上限从100提升至250以适应更长的智能体工作轨迹。
IFBench因分数饱和被移除——该基准已无法有效区分前沿模型。Artificial Analysis表示仍会继续运行IFBench并在新模型发布时公布结果,但不再将其纳入智能指数计算。调整后,v4.1共包含9项评估:GDPval-AA v2、τ³-Banking、Terminal-Bench v2.1、SciCode、Humanity's Last Exam、GPQA Diamond、CritPt、AA-Omniscience和AA-LCR,四大类别(智能体、编程、通用能力、科学推理)各占25%权重不变。
排名结果:Fable 5领跑但不可用,开源模型差距仍在
v4.1排名中,Claude Fable 5(使用Opus 4.8作为后备模型,得分60)以4分优势位居榜首,但该模型目前因美国商务部出口管制处于全球停用状态。这使得Claude Opus 4.8(max配置,得分56)成为当前实际可用的最高分模型,以1分优势领先GPT-5.5(xhigh配置,得分55)。
开源权重模型方面,DeepSeek V4 Pro(max,44分)和MiniMax M3(44分)并列领先,紧随其后的是Kimi K2.6(43分)和MiMo-V2.5-Pro(42分)。闭源与开源之间仍存在12分的差距(56 vs 44),但开源阵营内部的竞争已非常密集——前四名仅差2分。
新维度:每任务成本揭示效率差异
v4.1最有实际参考价值的变化是新增的三项每任务指标,计算方式是将模型运行完整智能指数所需的总成本、总时间和总输出Token数除以评估任务总数。
成本方面,Claude Fable 5每任务成本3.25美元(不可用),Claude Opus 4.8每任务1.78美元,GPT-5.5每任务0.99美元。DeepSeek V4 Pro每任务仅0.04美元——在智能指数上落后Opus 4.8约12分,但成本仅为后者的四十五分之一。换一种表述:Opus 4.8每多得1分需要额外支付约0.14美元/任务,而从DeepSeek V4 Pro到GPT-5.5每多得1分的边际成本约为0.086美元/任务。对于对成本敏感但不追求极致得分的应用场景,性价比的分水岭在开源与闭源之间非常明显。
时间方面,每任务推理时间从Grok 4.3(high)的1.5分钟到Claude Sonnet 4.6(max)的13.5分钟不等,差距约9倍。Opus 4.8每任务6.4分钟,GPT-5.5为3.7分钟。值得注意的是Gemini 3.1 Pro Preview以1.6分钟/任务获得46分,在时间效率维度表现突出。 此外,v4.1开始报告缓存输入Token及其对成本的影响,使实际运行成本的计算更接近真实使用场景。
对这一指数本身的几点观察
首先需要明确的是,Artificial Analysis智能指数是业界引用率较高的第三方综合评估之一,但它本身也是一种设计选择的产物。四大类别各25%的等权重分配意味着一个在智能体任务上极强但科学推理较弱的模型,和一个相反特性的模型可能获得相同的综合分数。对于有明确应用场景的开发者来说,分类别成绩可能比综合分更有参考价值。
其次,v4.0到v4.1的基准替换导致分数不能直接跨版本比较。v4.0中GPT-5.5曾以60分领跑,v4.1中降为55分;Opus 4.8从v4.0的某一分数变为56分。这种波动是方法论升级的正常结果,但也提醒读者不宜将版本间的分数变化解读为模型能力的退步或进步。
第三,值得关注的是这次更新中Fable 5的位置。由于该模型目前处于停用状态,其v4.1分数可能是在停用前已完成的测试结果。如果Fable 5的出口管制长期持续,一个不可用模型持续占据排行榜榜首将对指数的实用参考价值产生影响。
每任务成本和每任务时间的引入是v4.1最实际的贡献——它将基准测试从"谁最聪明"推向"智能的获取成本是多少",对需要在能力和预算之间做取舍的开发者和企业用户有直接参考意义。