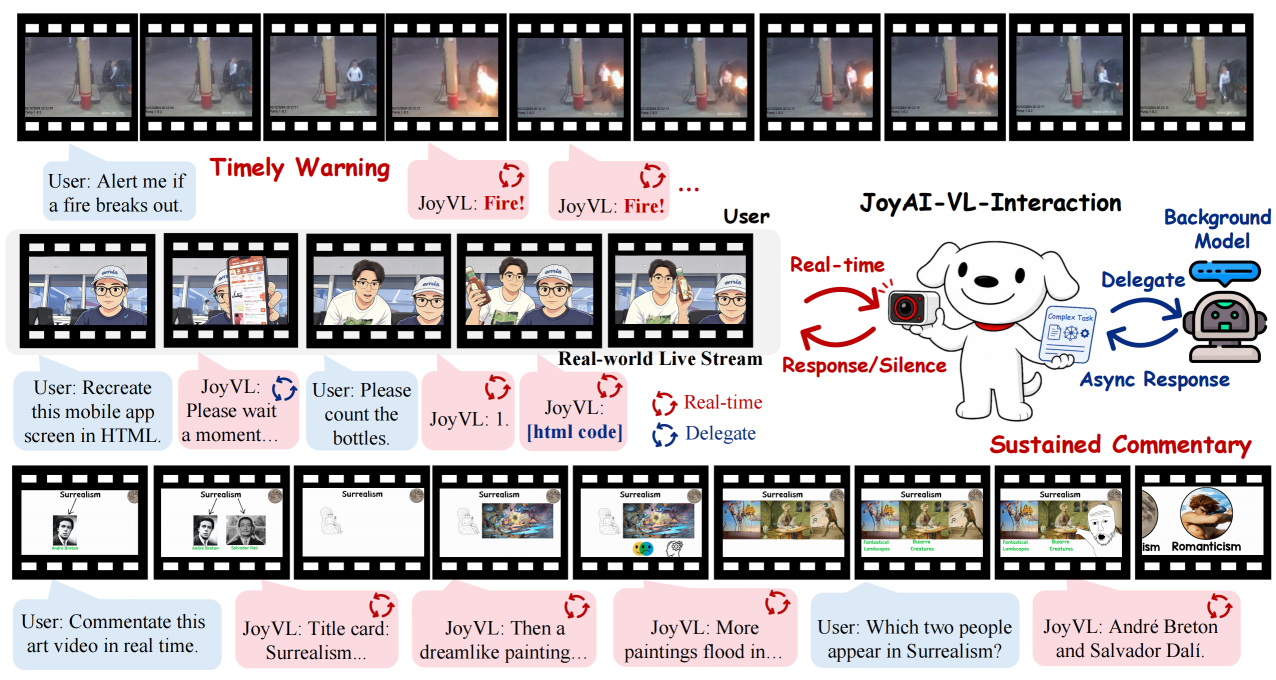
6月16日消息,京东未来学院(Joy Future Academy)视频理解团队发布JoyAI-VL-Interaction,一个8B参数规模的实时视觉-语言交互模型,连同训练方案、数据和完整部署系统一并开源。该项目对标5月11日由Mira Murati的Thinking Machines Lab(TML)提出的"交互模型"(Interaction Model)概念,核心差异在于JoyAI完全开源,而TML-Interaction-Small目前仅限闭源研究预览。
什么是"交互模型":从轮次对话到持续在场
理解这个项目首先需要理解它试图解决的问题。当前主流AI模型——无论是聊天、语音通话还是视频分析——都采用轮次对话(turn-based)设计:用户发起请求,模型生成回答,一轮结束。即使是打着"实时"标签的语音产品,底层仍然是"等你说完→思考→回应"的流程。
TML在5月提出的"交互模型"概念试图打破这一范式:模型持续观察环境(视频流、音频流),每一时刻自主判断应该开口说话、保持沉默还是将复杂任务交给后台处理。据TML博客描述,其TML-Interaction-Small是一个276B参数的MoE模型(12B活跃参数),以200毫秒为单位进行"微轮次"(micro-turn)处理,能够同时听、看、说。不过该模型目前处于闭源研究预览阶段,训练数据、训练方法和定价均未披露,更广泛的开放计划排在2026年下半年。
JoyAI-VL-Interaction采用类似的设计理念但走了完全不同的开放路线。据项目博客描述,该模型每秒持续处理视频帧,自主决定何时开口、何时沉默、何时将任务委派给后台Agent(支持通过OpenClaw或Claude Code执行复杂数字任务)。模型参数量仅8B——比TML的12B活跃参数还小,但团队声称在与豆包和Gemini的视频通话助手进行的58个录制场景的人工对比评测中,在"说了什么"和"何时说"两个维度上均获得了显著偏好优势。 九项能力与两个意外发现
JoyAI-VL-Interaction展示了九项核心能力:实时翻译(跟随视频字幕变化逐句翻译)、监控报警(火灾或人员跌倒时秒级告警)、应用引导(逐步指导用户操作手机屏幕)、实时解说、实时计数、时间感知、5分钟以上长视觉记忆、视觉驱动交互(如识别新进入画面的人并主动问候),以及Agent任务委派。
团队特别提到了两个未预期的涌现能力。第一,在训练数据中完全不包含应用界面视频的情况下,模型自发学会了引导用户完成手机购物流程。第二,仅凭400万样本的训练,模型就展现出了"何时应该说话"的时机判断能力——团队将其形容为一种"情商",并指出很多参数更大的模型反而需要依赖外部轮询机制,反应总是慢一拍。
竞争定位:开源8B vs 闭源276B
将JoyAI-VL-Interaction放在"交互模型"的竞争版图中,其定位特征非常明确:它可能是目前唯一完全开源的实时视觉-语言交互模型全栈,包括模型权重、训练方案、训练数据和部署系统。
在参数量和架构上,它和TML-Interaction-Small存在数量级差异——8B vs 276B MoE(12B活跃)。在评测方面,TML使用了FD-bench V1/V1.5、Audio MultiChallenge等标准化基准,而JoyAI目前仅提供了与豆包和Gemini的人工对比评测,未使用相同基准,因此两者无法直接比较性能。
值得注意的是京东在JoyAI品牌下的持续投入。此前该团队已发布JoyAI-Image(图像理解/生成/编辑统一基础模型,8B MLLM + 16B MMDiT)和JoyAI-Echo(长视频+音频生成框架,支持5分钟跨模态一致性生成),均已开源。JoyAI-VL-Interaction的加入使京东形成了从图像到视频到实时交互的完整多模态开源矩阵。
需要留意的几个问题
首先,"在58个场景中人工评测优于豆包和Gemini"的对比存在一个重要的公平性问题:JoyAI-VL-Interaction是一个专门为实时交互设计和训练的模型,而豆包和Gemini的视频通话功能是在通用模型上附加的能力。用一个专用模型对比通用模型在其非核心能力上的表现,结论的外推性有限。此外,58个场景的评测规模也偏小。
其次,400万训练样本在当前大模型训练数据动辄数十亿的背景下是一个非常小的数字。这可以理解为效率上的优势,但也可能意味着模型在覆盖面和鲁棒性上存在短板——例如,App引导能力是否仅限于购物场景,还是能泛化到更多应用类型?博客中未提供这方面的系统性测试。
第三,"交互模型"这个概念由TML在5月提出后引发了行业关注,JoyAI的博客也明确引用了TML的定义。但需要注意的是,这一概念目前尚无业界公认的标准化定义和评测框架——据DataCamp报道,TML自己也承认该领域"缺乏共享的衡量方式"。在概念尚未稳定的阶段,率先开源完整实现的价值在于让更多研究者能够复现和验证,而非在尚未建立的标准下宣称领先。
论文:https://huggingface.co/papers/2606.14777
GitHub:https://github.com/jd-opensource/JoyAI-VL-Interaction
项目博客:https://joyai-vl-video-future-academy-jd.github.io/JoyAI-VL-Interaction/