扩散模型这两年的进步有目共睹。无论是FLUX还是Wan这类代表性的生成模型,在文生图、文生视频任务上都已经能输出分辨率高、细节丰富、语义也站得住脚的内容。可问题也很现实——这类模型几乎都要靠多步去噪才能完成一次生成,而每一步都意味着要把那个庞大的生成网络完整跑一遍,算力消耗自然水涨船高。
放到图像生成场景里,这种开销会直接影响交互式创作的响应速度,也会拖慢在线部署的效率;放到视频生成场景里,问题更突出——模型不仅要保证每一帧的空间细节,还得兼顾时间维度上的连贯性,计算负担成倍增加,推理效率的瓶颈也就更加明显。
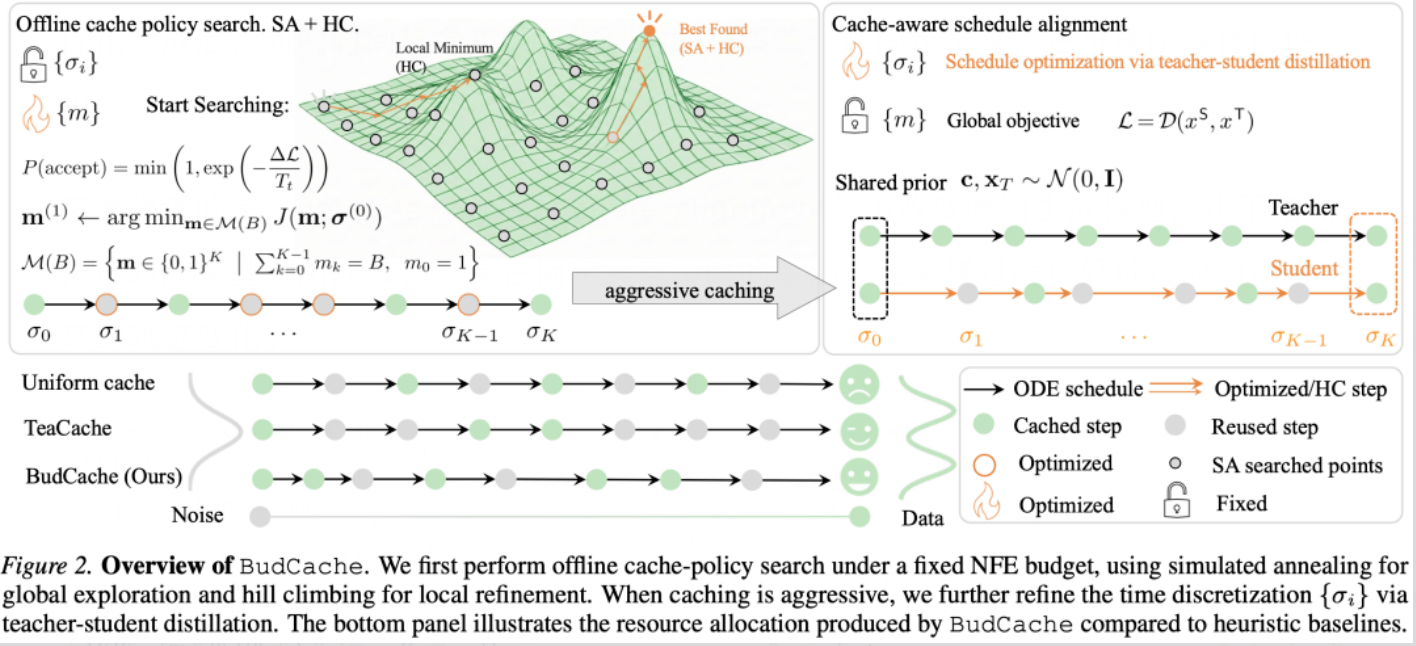
针对这个痛点,西湖大学AGI实验室提出了一种新的思路——BudCache,一种专门面向固定计算预算场景的扩散模型分步缓存(step-level cache)方法。和市面上常见的、依赖运行时阈值判断的缓存方案不同,BudCache换了一种做法:它不在推理过程中临时决定该不该算这一步,而是提前把推理预算锁定,再通过离线搜索的方式,找出这个预算下表现最好的缓存方案。这样一来,推理成本可以被严格控制在预设范围内,生成质量也能得到更好的保障。
这篇论文的第一作者是西湖大学AGI实验室研究助理雷明坤,论文由西湖大学助理教授张驰指导完成。
一、扩散模型为什么需要"缓存"加速
在多步去噪的过程中,相邻的几个步骤之间往往存在不少可以共用的信息。基于这一点,分步缓存方法的思路是:只挑出一部分关键的去噪步骤老老实实地跑完整模型,其余步骤则直接复用之前保存下来的输出或中间特征,从而省去大量重复计算。
这类方法有个明显的好处——不需要对模型重新训练,也不用改动模型本身的参数。对于FLUX、Wan这种已经训练完成的生成模型来说,缓存技术相当于一个即插即用的推理加速插件,可以直接嵌入到采样流程中。
像TeaCache、MagCache这些已有方案,已经验证了分步缓存这条路是可行的。不过目前大多数方法仍然是靠启发式规则来做缓存决策的——也就是在推理过程中根据某个实时信号,临时判断这一步到底要不要重新算,还是直接借用上一步的缓存结果就行。
这种做法确实能省下不少计算量,但也带来了两个绕不开的问题。
第一个问题是计算开销难以预估、难以控制。因为启发式阈值方法的实际计算量是由运行时信号触发的,不同的输入很可能触发不同次数的完整计算,导致最终的推理延迟波动较大、不够稳定。而在真实的部署环境里,大家往往更希望提前就能锁定一个明确的算力预算,而不是上线后才被动承受不确定的开销。
第二个问题是决策视野偏局部。某一步要不要复用缓存,通常只看当前这一步的误差或差异信号,并没有真正围绕最终生成效果去做全局优化。换句话说,单看每一步似乎都做出了"合理"的选择,但拼起来未必能形成一条全局最优的生成路径。
BudCache的核心思路,正是要换个角度重新定义这个问题:分步缓存的关键不该只是判断"这一步能不能省",而应该是在预算已经固定的前提下,搞清楚"到底哪几步最值得花算力去算"。为了评估一套缓存方案的好坏,BudCache不再只盯着单步的局部误差,而是直接看这套方案最终生成出来的结果——也就是用了这组缓存步骤之后产出的图像或视频,到底有多接近完整计算情况下的结果。
二、把"启发式阈值"换成"固定预算下的搜索"
BudCache把分步缓存这件事,重新表述成了一个带预算约束的离散优化问题。
具体来说,BudCache会先把模型实际需要前向计算的次数定死,也就是所谓的NFE预算。比如在一次包含若干个逻辑去噪步骤的采样流程里,可以提前规定只允许模型真正算8次、9次或10次,剩下的步骤全部走缓存复用。这样一来,推理成本在部署之前就已经确定好了,不会因为输入不同而产生难以预料的延迟波动。
在此基础上,BudCache用一个二进制掩码(mask)来表示具体的缓存方案:每个去噪步骤对应掩码里的一个位置,如果是1就执行完整的模型计算,如果是0就直接复用最近一次算出来的缓存结果。由于掩码中1的总数被严格限定为预算B,模型的实际调用次数也就被牢牢锁住了。
但找到一个真正好用的掩码并不容易。假设整个采样流程一共有K个逻辑去噪步骤,要从里面挑出B个去做真实计算,可能的组合数量是相当庞大的。更麻烦的是,扩散模型的去噪过程存在明显的前后依赖关系——早期某一步怎么选,会一路影响到后面整条采样轨迹,最终改变生成图像或视频的质量。所以简单的局部贪心策略很容易卡在局部最优解上,找不到真正高质量的缓存方案。
为了解决这个搜索难题,BudCache采用了"模拟退火+爬山算法"两阶段混合搜索策略。
第一阶段,用模拟退火做全局探索。模拟退火的特点是允许搜索过程在早期阶段接受一些暂时看起来更差的方案,靠这种方式跳出局部最优的陷阱,在更大的策略空间里去寻找潜在更好的候选方案。BudCache具体通过两类操作来生成新方案:一类是Swap,把一个计算步骤和一个缓存步骤的位置对调;另一类是Shift,把某个计算步骤挪到相邻的位置。这两种操作都不会改变总的计算预算,所以整个搜索过程始终满足固定NFE这个约束条件。
第二阶段,用爬山算法做局部精修。等模拟退火锁定到一个比较好的策略区域之后,BudCache会进一步检查当前方案附近的候选选项,挑出那些能让最终结果更贴近完整计算结果的方案,反复迭代,直到附近再也找不到更优的候选为止。
这种两阶段混合搜索的好处是,能用相对较小的离线成本找到质量不错的缓存方案。更关键的是,整个搜索过程只需要在部署前跑一次——真正做推理的时候,直接套用提前搜好的固定缓存方案就行,既不需要在线搜索,也不需要运行时再做阈值判断,因此完全不会给推理过程增加额外开销。
缓存方案搜索完成之后,BudCache还提供了一个可选的进阶步骤——cache-aware schedule alignment(缓存感知的时间步校准)。这一步可以理解为一个轻量级的离线校准模块:在缓存掩码已经固定不变的前提下,对采样过程使用的时间步进行优化调整,让缓存版采样器的最终输出能够更贴近完整计算的结果。
具体的做法是,把完整计算的采样过程当作"teacher",把套用了缓存的采样过程当作"student",然后去优化student所使用的时间步分布,让它的最终生成结果尽量逼近teacher。优化结束之后,新得到的时间步会和此前搜索出的缓存方案一起被固定下来,直接用于后续的推理。
需要说明的是,这一步的时间步校准并不会改变原始生成模型本身,也不会增加推理阶段的模型调用次数,它只是在缓存方案已经确定的基础上,让采样过程更好地适应缓存带来的轨迹变化。
三、在主流图像、视频生成模型上的实测表现
研究团队首先在当下主流的图像生成模型FLUX.1-dev上对BudCache进行了评测,并在DrawBench基准上和多种代表性缓存方法做了对比,包括TeaCache、MagCache、LeMiCa、DiCache、ERTACache以及TaylorSeer。结果显示,在同样的推理预算下,BudCache能够更好地保住生成质量。
从可视化的对比效果来看,BudCache在文字渲染、复杂结构和细节还原方面表现更稳。比如在生成包含"Google Brain Toronto"或"CLIMATE CHANGE"这类文字内容的图像时,部分启发式缓存方法容易出现字符错乱、拼写出错或文字模糊的问题,而BudCache能更准确地保留文字内容。在机械钟表、雕像结构、物体之间的相对位置关系等比较考验细节的场景中,BudCache同样表现出更好的几何细节保留能力和语义一致性。
在视频生成方向,研究团队进一步在Wan2.1-T2V-1.3B模型上做了实验。视频生成本身需要处理更长的视觉序列、更复杂的时空关系,对推理效率的要求自然也更苛刻。实验结果表明,BudCache在视频生成场景下同样有效:在Wan2.1-T2V-1.3B上,完整推理大约需要189秒,TeaCache约需100秒,而BudCache只需约82秒。与此同时,BudCache在PSNR、SSIM、LPIPS这几项指标上都优于TeaCache,这说明它不只是跑得更快,在保持视频重建质量这件事上也做得更到位。
从生成效果上看,BudCache即便在加速状态下也能保持更稳定的视频细节表现,比如人物服装的颜色、摩托车的外观、画面主体和背景之间的关系等,都能被更完整地保留下来。这也证明了BudCache这套固定预算搜索策略,不仅适用于图像生成,同样可以扩展到视频生成模型上。
四、泛化能力验证:搜出来的策略能不能"通用"?
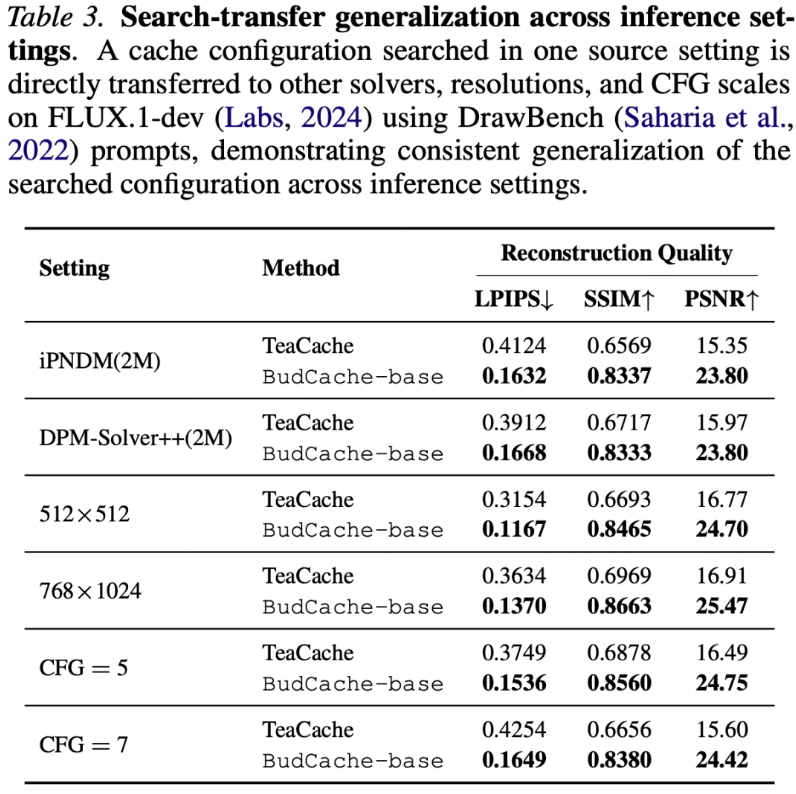
除了在固定设置下对比性能,研究团队还专门验证了BudCache的泛化能力。这里有个很关键的问题:离线搜索得到的缓存策略,是不是只对某一种特定配置有效?如果每换一次设置就得重新搜一遍,那这套方法在实际使用中的成本就会变得很高。
实测结果显示,BudCache搜出来的缓存策略具备不错的迁移能力。研究团队把在某个源设置下搜索得到的缓存方案,直接套用到不同的solver、不同分辨率、不同CFG scale等多种设置中,并在FLUX.1-dev上做了评估。结果表明,在这些差异较大的推理条件下,BudCache依然稳定地优于TeaCache,这说明搜索得到的缓存策略并没有过拟合到某一种固定的采样配置上。
BudCache这项工作的核心贡献,是把分步缓存这件事,从"靠启发式阈值临时触发"推进到了"在固定预算下做系统性的策略搜索"。以往大多数缓存方法关注的是如何根据运行时信号去判断当前这一步能不能复用缓存,而BudCache瞄准的是一个更贴近实际部署需求的问题:当推理预算已经定死的时候,到底哪些步骤才最值得花算力去真正计算?
通过对预算约束的建模、离线缓存策略搜索,再加上时间步校准这道工序,BudCache做到了在不重新训练模型、不改动原始模型参数、也不增加在线推理开销的前提下,为FLUX、Wan这类主流图像与视频生成模型提供了更可控的加速效果。
总的来说,BudCache提供了一套更适合实际部署的扩散模型缓存加速方案——既能把推理成本严格限定在预算范围内,又能在这个预算之下尽量保住生成质量,为图像和视频生成的高效推理探出了一条新路径。