近日 Anthropic 突发上线 Claude Sonnet 5(代号 Fennec),这是迄今为止 Agent 属性最强的 Sonnet 系列模型,整体性能大幅逼近旗舰级 Opus 4.8,且已全面向免费及 Pro 订阅用户开放,成为默认使用模型。
在高端模型普遍收紧访问权限的行业背景下,这款中端模型的能力跃升,为开发者提供了高性价比的生产力替代方案,也重塑了大模型中端市场的竞争格局。
一、核心性能跃升:多维度追平旗舰 Agent 能力成最大亮点
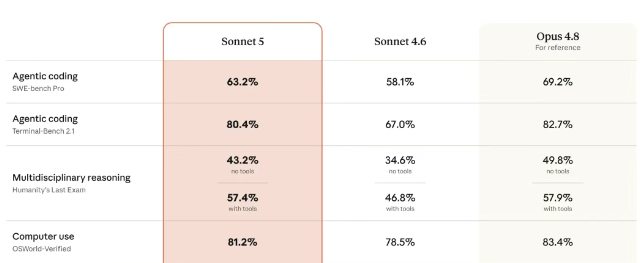
Sonnet 5 的升级集中在推理、工具调用、编程与知识工作四大维度,整体能力达到 Opus 4.8 的 90%-100% 区间,实现了中端产品向旗舰门槛的跨越。
编程领域是传统优势赛道,SWE-bench Pro 得分 63.2%,超越 GPT-5.5 的 58.6%,仅略低于 Opus 4.8 的 69.2%;Terminal-Bench 2.1 得分 80.4%,较上代提升 13 个百分点,与旗舰模型差距不足 2%。
跨学科推理测试 Humanity's Last Exam 中,带工具版本得分 57.4%,与 Opus 4.8 仅差 0.5 个百分点,大幅领先同价位竞品。
电脑操控能力 OSWorld-Verified 得分 81.2%,同样反超 GPT-5.5,直追旗舰水平。更具标志性的是知识工作场景,GDPval-AA v2 得分 1618 分,实现了对 Opus 4.8 的反超。
作为主打 Agent 能力的版本,它可自主制定执行计划、调用浏览器与终端工具,这类深度自主执行能力在数月前还仅旗舰模型具备,如今下沉到中端产品线,直接拉低了智能体工作流的应用门槛。
二、定价策略:限时促销拉低门槛 暗藏分词器膨胀细节
价格是 Sonnet 5 最具市场冲击力的优势,官方同时推出了限时促销政策与长期定价体系。
API 限时促销价为输入 2 美元 / 百万 Token、输出 10 美元 / 百万 Token,活动持续至 8 月 31 日;恢复原价后为输入 3 美元、输出 15 美元,仅为 Opus 4.8 定价的六成。对比同级别竞品,其促销期成本仅为 GPT-5.5 标准版的三分之一左右,性价比优势显著。
但产品细节中暗藏成本变量:全新的 tokenizer 分词器会使相同文本的 Token 计数出现 1.0-1.35 倍的膨胀,原价恢复后实际使用成本会较上代有所上升。即便如此,对比旗舰模型仍有明显成本优势,尤其对多 Agent 并行架构场景,同等预算可支持 2-3 倍的 Agent 并发量,大幅降低了规模化智能体工作流的落地成本。
三、安全能力反超:中端模型刷新防御基准
安全对齐是 Sonnet 5 最被低估的升级项,多项防御指标甚至超越家族旗舰,打破了 “中端模型安全能力缩水” 的行业惯性。
提示注入攻击成功率仅 0.19%,与 Opus 4.8 持平,远低于 GPT-5.5 的 3.08%。浏览器注入防御表现尤为突出,攻击成功率仅 0.93%,大幅优于 Mythos 5 的 29.7% 与 Opus 4.8 的 31.5%,开启防护后可降至 0%。恶意代码注入防御较上代提升 150 倍,攻击成功率从 45.26% 降至 0.29%。
漏洞利用测试中,它完全无法生成可用的漏洞利用程序,实现了强业务能力与低安全风险的平衡。不过在不对齐行为评分上,2.53 分的表现优于上代,但仍略高于旗舰系列,体现出模型能力增强后,安全对齐与自主性之间的平衡仍有优化空间。
四、市场定位:精准卡位腰部市场 重构竞争格局
Sonnet 5 的发布是一次精准的中端市场卡位:向上能力触达旗舰门槛,可覆盖绝大多数开发、办公、Agent 场景;向下价格贴近普惠区间,精准填补了 “旗舰太贵用不起、低端能力不够用” 的市场空白。
在高端模型纷纷收紧访问、提升使用门槛的行业背景下,这款全面开放的高性价比模型,快速承接了大量开发者的生产力需求。从行业竞争视角看,当多数厂商聚焦旗舰模型跑分竞赛时,Anthropic 选择强化中端产品线的能力与性价比,本质是用成熟技术下沉抢占规模化落地市场。
对绝大多数开发者而言,日常的 Bug 修复、代码重构、工具调用等工作,Sonnet 5 已完全能够胜任,无需为少量极限场景支付旗舰模型的溢价。它也将成为接下来相当长一段时间内,主流开发与办公场景的高性价比主力选型,推动大模型生产力工具向更广泛的用户群体渗透。