
语音到检索(S2R):语音搜索的全新技术方案
如今,语音搜索由我们全新的语音到检索(Speech-to-Retrieval,简称S2R)引擎提供支持。该引擎可直接从您的语音查询中获取答案,无需先将语音转换为文本,从而为所有用户带来更快、更可靠的搜索体验。
基于语音的网页搜索早已出现,且至今仍被众多用户使用。其底层技术发展迅速,适用场景也在不断拓展。谷歌最初的语音搜索方案采用自动语音识别(Automatic Speech Recognition,简称ASR)技术,将语音输入转换为文本查询,再搜索与该文本查询匹配的文档。然而,这种“级联建模”方案存在一个问题:语音识别阶段哪怕出现微小误差,都可能大幅改变查询的含义,进而导致搜索结果偏差。
举个例子:假设有人通过语音搜索爱德华・蒙克(Edvard Munch)的著名画作《呐喊》(The Scream)。若搜索引擎采用典型的级联建模方式,会先通过ASR将语音查询转换为文本,再将文本传递给搜索系统。理想情况下,ASR能完美转录查询内容,搜索系统接收到“the Scream painting”(《呐喊》画作)这一正确文本后,会返回相关结果,比如这幅画的历史背景、创作寓意及展出地点等。但如果ASR系统将“scream”中的“m”误听为“n”,就会把查询解读为“screen painting”(屏幕绘画),最终返回关于屏幕绘画技巧的无关结果,而非蒙克这幅杰作的相关信息。
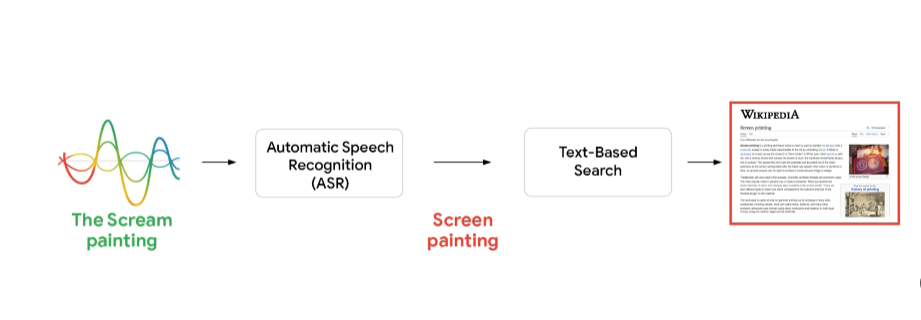
ASR的准确性是语音搜索的关键。对比以下两种情况即可明了:一是系统正确转录查询内容,二是系统转录出现错误,两者的搜索结果差异显著。
为避免网页搜索系统出现此类误差,我们不妨设想:能否让系统直接将语音映射到目标检索意图,完全绕过文本转录这一步骤?
语音到检索(S2R)技术应运而生。从核心原理来看,S2R是一种无需经过“生成完美文本转录本”这一中间步骤(且该步骤存在潜在误差),就能直接解读语音查询并从中检索信息的技术。它代表了机器处理人类语音的架构性与理念性根本转变:当前主流的语音搜索技术聚焦于“用户说了哪些词?”这一问题,而S2R则旨在回答一个更具价值的问题——“用户在寻找什么信息?”。本文将探讨当前语音搜索体验中存在的显著质量差距,并说明S2R模型如何填补这一差距。此外,我们还将开源简单语音问题(Simple Voice Questions,简称SVQ)数据集——该数据集包含17种语言、26个地区的简短语音问题音频,是我们用于评估S2R性能潜力的核心资源,同时也是全新“大规模声音嵌入基准测试(Massive Sound Embedding Benchmark,简称MSEB)”的组成部分。
一、S2R性能潜力评估
传统ASR系统将音频转换为单一文本字符串时,可能会丢失有助于消除语义歧义的上下文线索(即“信息丢失”)。若系统在早期阶段就误解了音频内容,这一误差会直接传递给搜索引擎,而搜索引擎通常缺乏修正该误差的能力(即“误差传播”)。最终,搜索结果可能无法反映用户的真实意图。
为探究这一关联,我们设计了一项实验来模拟“理想ASR性能”:首先,我们收集了一组具有代表性的测试查询,这些查询与典型的语音搜索流量一致;关键在于,随后我们让人工标注员对这些查询进行手动转录,从而构建了一个“完美ASR”场景——此时的转录结果是绝对准确的。
之后,我们建立了两个截然不同的搜索系统用于对比(见下方图表):
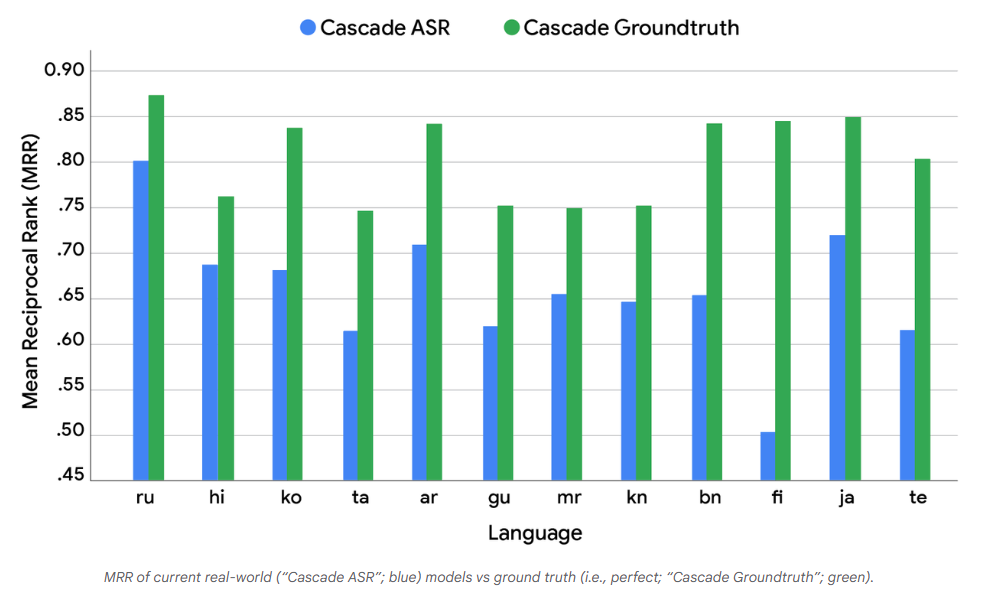
级联ASR(Cascade ASR):代表现实世界中的典型设置——先通过ASR系统将语音转换为文本,再将文本输入检索系统。
级联基准(Cascade Groundtruth):将完全准确的“基准文本”直接输入同一个检索系统,以此模拟“完美”的级联模型。
随后,我们将两个系统(级联ASR和级联基准)检索到的文档,连同原始的真实查询一起呈现给人工评估员(即“评分者”)。评估员的任务是对比两个系统的搜索结果,并对其各自的质量给出主观评价。
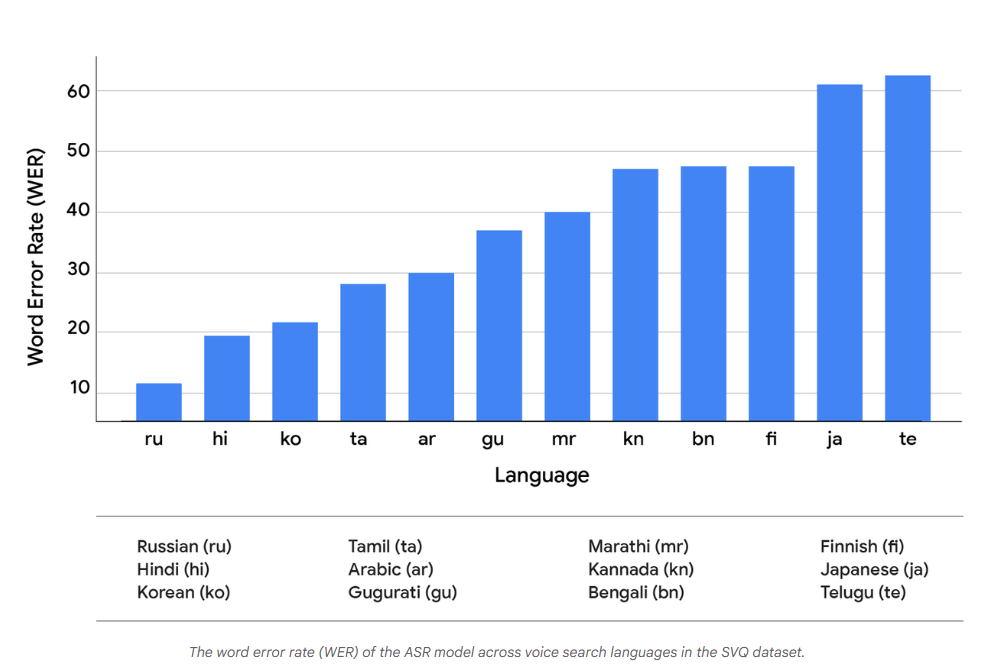
我们采用词错误率(Word Error Rate,简称WER)来衡量ASR质量,采用平均倒数排名(Mean Reciprocal Rank,简称MRR)来衡量搜索性能——MRR是一种用于评估“为一组查询生成按正确性概率排序的候选响应列表”这一过程的统计指标,计算方式为:对所有查询的“首个正确答案排名的倒数”取平均值。
通过对比“现实系统”与“基准系统”在WER和MRR上的差异,我们可以看出SVQ数据集中一些最常用语音搜索语言的性能提升潜力(见下方图表)。
图表1:SVQ数据集中各语音搜索语言对应的ASR模型词错误率(WER)(原文标注:SpeechToRetrieval3_WER)
图表2:当前现实系统(“级联ASR”,蓝色)与基准系统(“级联基准”,绿色)的平均倒数排名(MRR)对比(原文标注:SpeechToRetrieval4_MRRCurrent)
这一对比结果得出了两个关键结论:第一,对比上述两张图表可发现,在不同语言中,“更低的WER”并不一定会可靠地带来“更高的MRR”。两者的关系十分复杂,这表明WER指标并未完全捕捉到转录误差对下游任务的影响——误差的具体性质(而非仅仅是误差的存在)似乎是一个关键因素,且该因素与语言相关。第二,更重要的是,在所有测试语言中,两个系统的MRR都存在显著差异。这表明当前的级联设计与“理想语音识别下的理论最佳性能”之间存在巨大的性能差距——而这一差距恰恰证明,S2R模型在从根本上提升语音搜索质量方面具有明确潜力。
二、S2R的架构:从声音到语义
我们的S2R模型核心是双编码器架构(dual-encoder architecture)。该设计包含两个专门的神经网络,通过从海量数据中学习,理解语音与信息之间的关联:
一个是音频编码器:处理查询的原始音频,将其转换为能够捕捉语义含义的丰富向量表示。
另一个是文档编码器:以类似方式学习文档的向量表示。
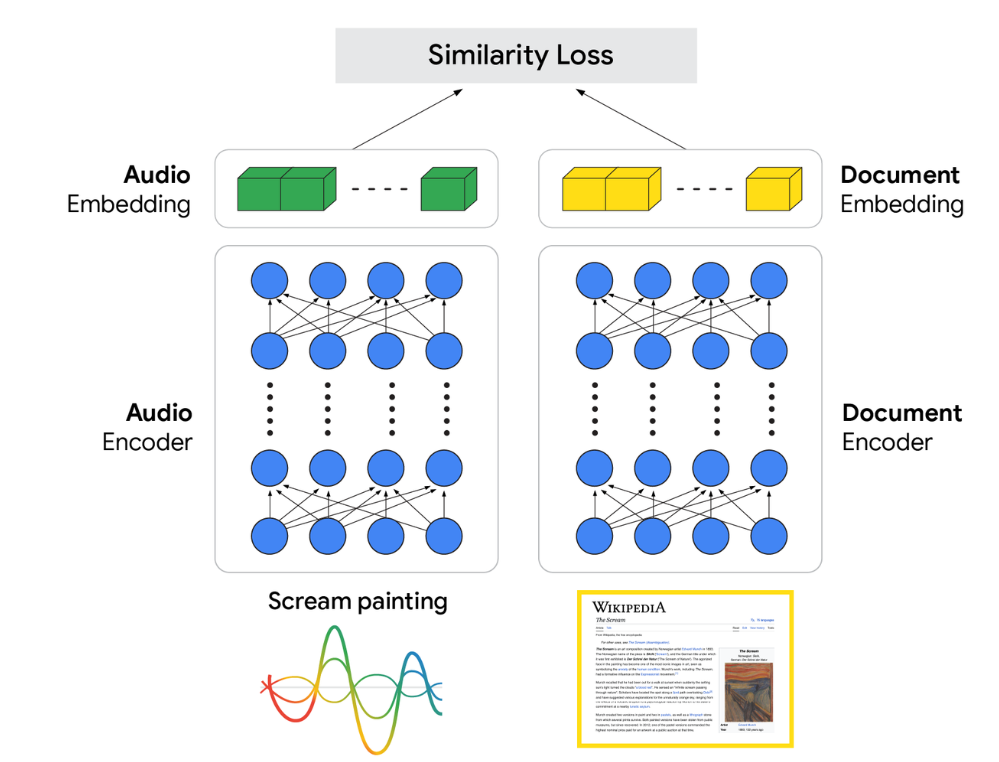
图表3:音频嵌入与文档嵌入之间的相似度损失差异(原文标注:SpeechToRetrieval5_SimilarityLoss)
该模型的关键在于训练方式:我们使用包含“语音查询-相关文档”配对的大型数据集,对两个编码器的参数进行同步调整训练。
训练目标是确保:在表示空间中,语音查询的向量与对应文档的向量在几何位置上足够接近。这种架构使模型能够直接从音频中学习“检索所需的核心意图”,完全绕过“逐词转录”这一脆弱的中间步骤——而这正是级联设计的主要缺陷。
三、S2R模型的工作原理
当用户说出查询内容时,音频会被传输到预训练的音频编码器中,生成一个“查询向量”。随后,该向量会通过复杂的搜索排序流程,从我们的索引中高效筛选出高度相关的候选结果集。
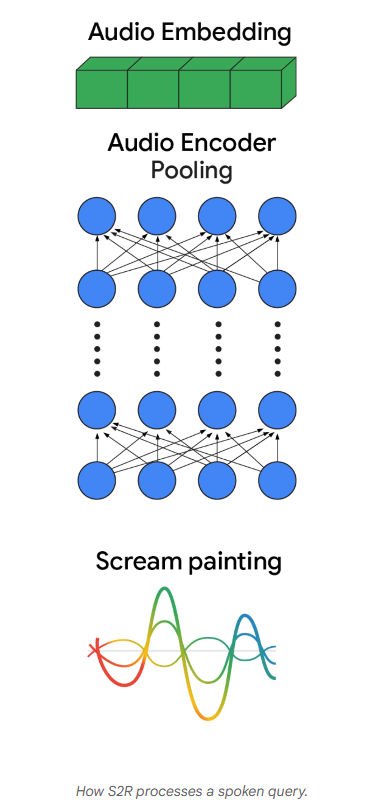
(原文标注:S2R如何处理语音查询的动画演示)
上述动画展示了S2R如何理解并响应语音查询:首先,用户发出语音请求“《呐喊》画作”(The Scream painting);接着,音频编码器将声音转换为“丰富的音频嵌入”——这是一种能够代表查询深层语义的向量;然后,该嵌入会用于扫描海量文档索引,筛选出初始的高相似度候选结果,例如《呐喊》的维基百科页面(相似度0.8)和蒙克博物馆官网(相似度0.7)。
但找到相关文档仅仅是第一步。至关重要的最终步骤由搜索排序系统主导:这一强大的智能系统不仅依赖初始相似度评分,还会将其与数百个其他信号结合,深入理解结果的相关性与质量;它能在瞬间整合所有这些信息,完成最终的排名排序,确保向用户呈现最有帮助、最可靠的信息。
四、S2R的性能评估
我们在SVQ数据集上对上述S2R系统进行了评估:
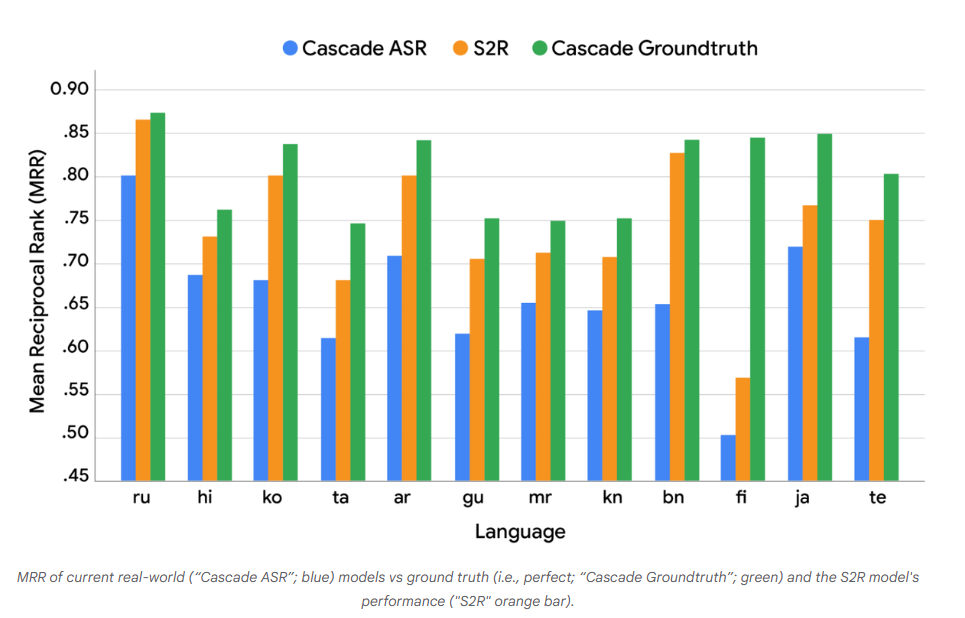
图表4:当前现实系统(“级联ASR”,蓝色)、基准系统(“级联基准”,绿色)与S2R模型(橙色)的平均倒数排名(MRR)对比(原文标注:SpeechToRetrieval7_Results)
S2R模型的性能(橙色柱)呈现出两个关键结果:
显著优于作为基准的级联ASR模型;
性能已接近“级联基准模型”设定的上限。
尽管结果令人鼓舞,但两者之间仍存在差距,这表明还需要进一步的研究与优化。
五、语音搜索的新时代已正式到来
采用S2R驱动语音搜索并非理论探索,而是已落地的现实。通过谷歌研究院(Google Research)与搜索团队(Search)的紧密合作,这些先进模型目前已在多语言场景中为用户提供服务,相比传统级联系统,其准确性实现了显著飞跃。
为推动整个领域的发展,我们还将SVQ数据集作为“大规模声音嵌入基准测试(MSEB)”的一部分进行开源。我们相信,共享资源与透明评估能够加速技术进步。秉持这一理念,我们诚挚邀请全球研究社区使用该数据集,在公开基准测试中验证新方案,并共同参与构建下一代真正智能的语音交互系统。
本文来源于:Speech-to-Retrieval (S2R): A new approach to voice search