
文化感拉满,一致性翻车,没想到混元3.0是这样的AI设计师!

前言
文字主导类
视觉绘制类
虚拟试衣类
写在最后
(ps:下面除操作界面截图外,其余所有图均由AI生成)
文字主导类
文字设计

(左为中文指令生成,右为英文指令生成)

(上为中文指令生成,下为英文指令生成)

(上为中文指令生成,下为英文指令生成)

(中文指令生成)
你看,无论是英文指令还是中文指令,无论是呈现中文还是英文,都不影响它的呈现效果。
字体、花纹、笔力等各要素,皆能被混元生图3.0描画得光彩夺目。
混元生图3.0文字设计细腻,对不同语言文字和文化理解到位的优点,就显现出来了。
再看看它的操作界面。
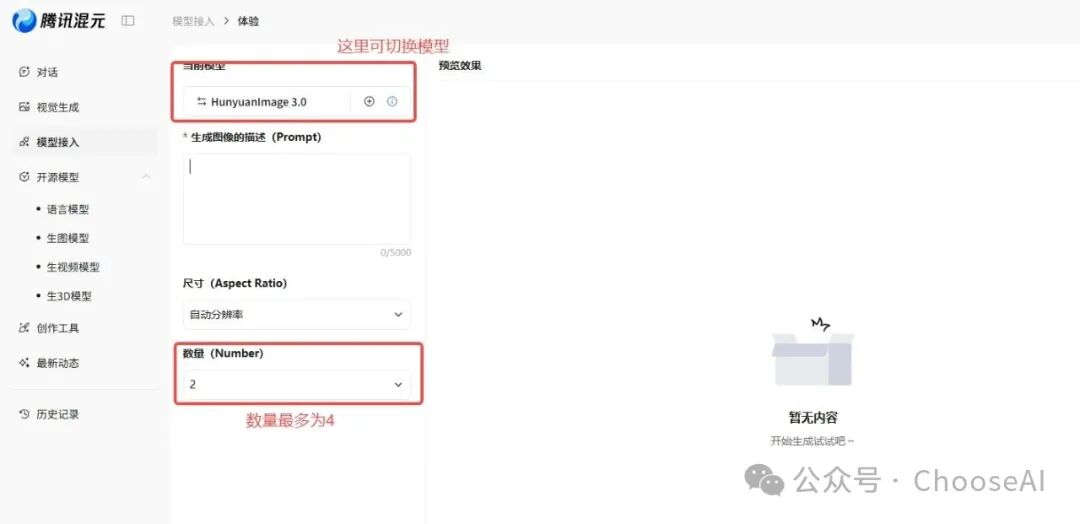
其实很简单,只要你输入提示词,选择尺寸和数量(一次性生成图片的数量,这里最多为4)就行了。
知识卡片
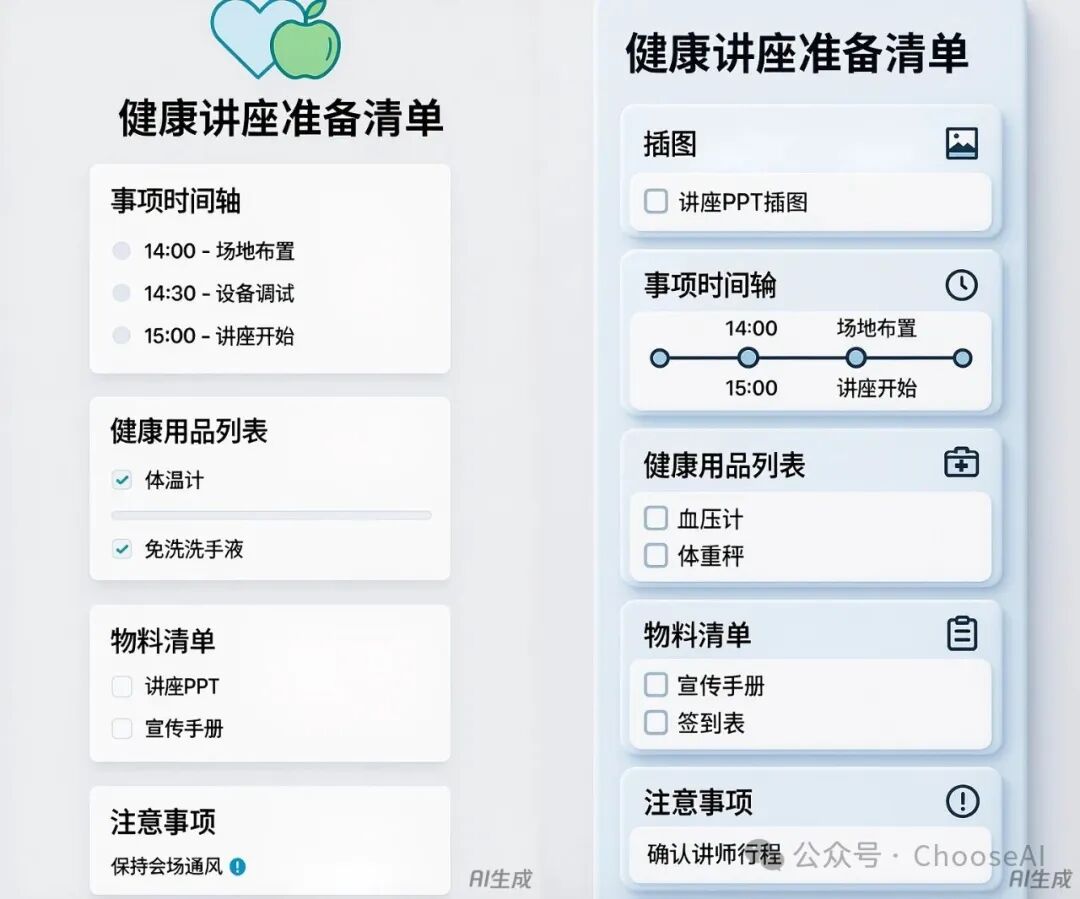
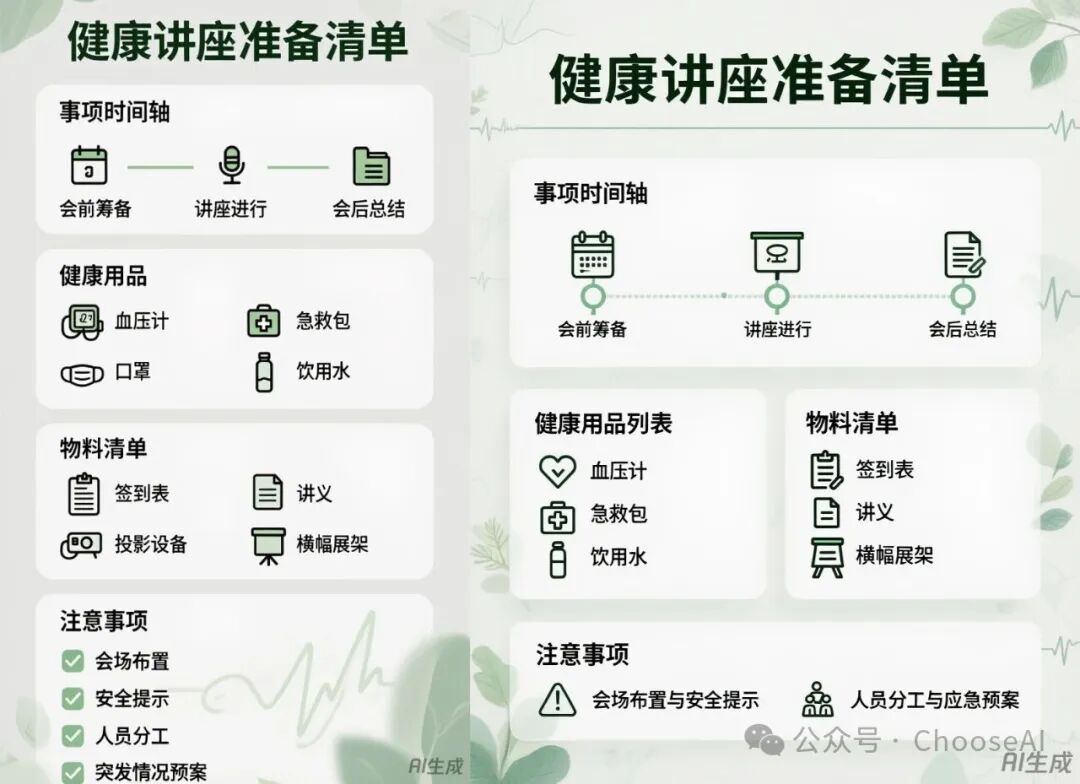
第一组图片由简单一句话的提示词生成,第二组图片的提示词更复杂、细节更多。
可以发现,第二组图片比第一组美观多了,不仅添加了底纹设计,还丰富了图标和文字内容。
只是两组图片都有展示不全的缺点。
混元生图3.0可以根据简单提示词有模有样地设计卡片,但不会根据需求量灵活设计排版,更不能发挥能动性掌控细节、给人以舒适的美感。
视觉绘制类
表情包


两组图的主角都可可爱爱,不过第一组图的主角形象是拟人版的猪,但并不是八戒。第二组图从主角的穿着、言行能看得出来是八戒,但是有些细节(如钉耙)容易让人出戏,中文偶有错误或不清。
造梗就更不用提了,混元生图3.0相比即梦还是嘴笨,不会讲段子、不会玩梗,更不会为每个梗搭建场景。
不同视角


真是让人笑出鹅叫。
同场景异视角的图(第一组图)还好,环境和动物没有保持一致性,但小男孩还能看得出来是同一个人。
但异场景异视角的图(第二组图)就令人大跌眼镜了,实属buff叠满。
一来就表情崩坏,再是分身相见,最后是多出来的女朋友?
集齐了恐怖、魔幻和青春校园文学,主打一个跨界乱炖。
而我之前苦苦追求的一致性,竟然由一只彩色飞鸟成全了。
果然是个魔幻的世界!
漫画绘本


生成一个关于老爷爷的四格童话漫画。


生成一个关于黑猫和小女孩的四格恐怖漫画,要有对话。
这里就要夸一夸混元生图3.0了。四格漫画的提示词非常简单,20个字以内的提示词就能产出美观、有看头的故事漫画,能自主选择黑白或者彩绘风格,比之前测的banana和即梦4.0都要省心。
banana、即梦4.0的文生漫画,细节一致性不容易得到保障,图生漫画会多出定妆或把控故事走向的流程。
而混元生图3.0,不需要你想出故事具体情节,只需给定主角、场景、故事核心词的任一一个元素就行了。
当然混元生图3.0一次性产出四格漫画所衍生的问题也不少。
比如修改就是再次生成。因为它没有历史记忆功能,只能文生图。若你对生成的第一格漫画不满意,这时并不能通过对话修改,只能再次生成。

比如有对话的漫画时有漏洞。上面展示的有对话的黑白漫画,看着很流畅,但那只是我抽盲盒运气好。当你输入有对话的提示词后,你可能会遇见主角变了、主角半身埋土里等问题。
所以,若你想要生成次抛的无对话漫画,混元生图3.0是个不错的选择,但若你想要生成连载的有对话漫画,最好还是看向banana和即梦4.0。
虚拟试衣类


因为不能上传附件,所以混元3.0的图像重组以“生成待处理的图”取代了上传附件的步骤。
其实是“生图-识别分析-生图-一致性控制”的过程。
从生成的结果看,它对指令的理解到位,图像生成对齐和虚拟试衣的功能表现都比较良好,服装鞋包还原度可以说是100%。
对于电商从业者而言,这真是商品展现的好帮手,可以省下不少找真人模特的成本。
写在最后
这里小结一下混元生图3.0的特点:
1.它国内国际语言和文化通吃,不似混元实时生图2.0对国内文化理解能力弱;
2.它创作漫画时的一致性会更好;
3.它察言观色能力弱,只能听懂你给出的明确要求,不能听出“潜台词”,不会主动优化细节;
4.它记忆不行,没有历史记录,需要用户当场保存结果;
5.它造梗能力弱,不能融入社会现象创作;
6.它在生成文字设计类图像方面,有明显的排版漏洞。
所以,当你身处如下场景时,选择混元生图3.0能助你顺风顺水:
想不掏钱生成短频快、质量过关的图片,想创作单次任务量小、任务图关联性不大、可忽略细节的图片,想批量生成文字设计类的图片和短漫画。
今天的分享就到这里了,欢迎在评论区留言分享你使用“混元生图3.0”的体验,想获得本篇所有图片提示词的童靴可入群询问~
我们AI产品活动正在火热进行!有奖品和现金福利,活动详情如下:
投稿活动:https://www.chooseai.net/activity/camp
测评活动:https://www.chooseai.net/activity/recruit

