不知道你是否在视频创作的时候同我一样都有这种感受。就是会兜兜转转很久。要么就是在融合热梗与热点中冥思苦想很久,要么就是被困在视频的配音、字幕中很长一段时间。用AI生成视频吧,说实话,目前视频生产链完整、生成质量还不错、性价比高的国内AI产品,还真不多。字节的即梦,它的图和视频的功能是分开的,画布是生图专属;快手的可灵,虽然画布可以“图-视频-音效”一条路走下去,但bgm和文案还是需要自己配,而且生成多个视频的性价比也不算高。
不过上周五,剪映团队推出了“小云雀”agent。我试了后,可以肯定地告诉大家,若你要做1分钟内的视频,它能省去你“生成多分镜视频-配人声-配音效和bgm-剪辑”的创作链条。
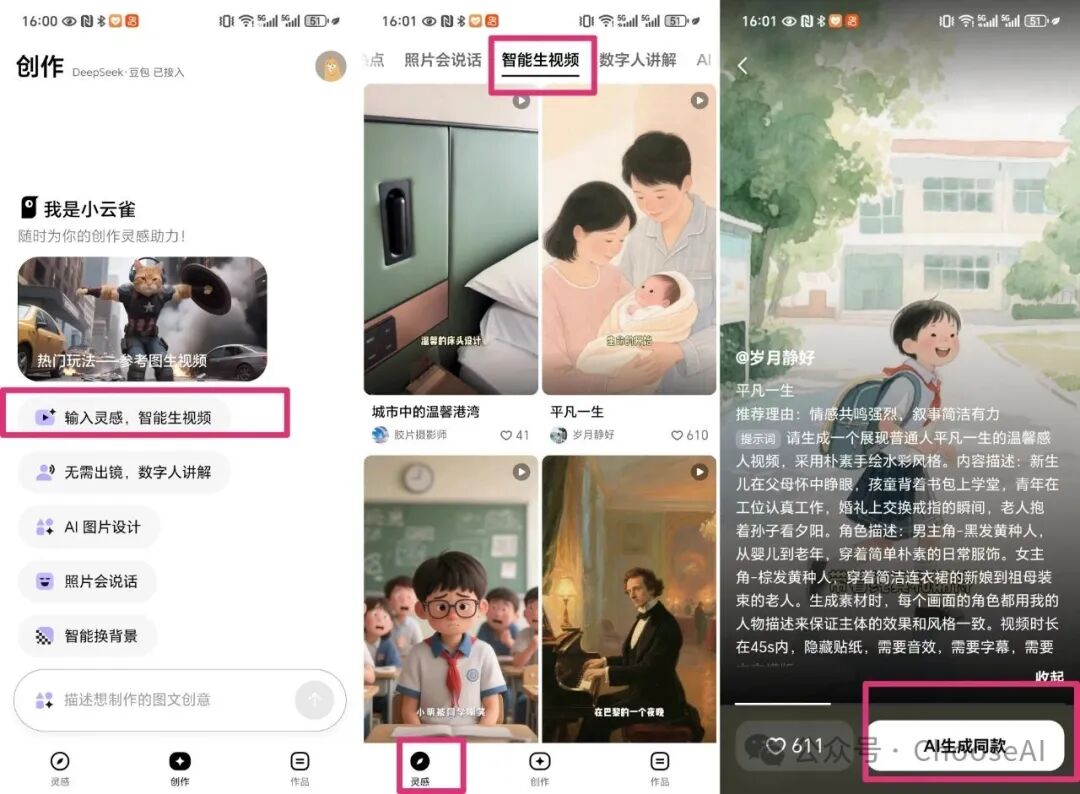
而且,它到目前为止还完全免费,虽然也会限制次数,但1天能生成10多个视频,相比其他需要充值、花大额积分的同类产品,也很香了!官方介绍它的特效采用剪映上内容,内容创作采用的豆包模型,语义理解采用的DeepSeek 大语言模型算法。它还能调用抖音的热点数据和模板资源。那它具体效果怎么样呢?下面我将举多个例子,让大家看到它不同功能的实际效果。“智能生成视频”的“智能”在于它是升级版的文生视频,几句话就能包揽你视频创作全过程,且让生成的视频内容完整。
你可以在“创作”界面点击对应功能进入,输入提示词。也可以从“灵感”进入,看他人的作品,用他人的指令生成同款或当作指令模板。
当然不仅是“智能生成视频”这个功能可看见他人的指令,小云雀的所有功能都能看见他人指令,这是它的伟大之处。
我套用他人的指令模板设计了自己的创意视频,结果如下:
仙女介绍天庭
提示词:做一个天庭背景的视频,让一个仙女姐姐(附件的人物形象)用古风味足的话为观众介绍天庭每个景点(包括南天门、诛仙台、瑶池等)。要融入网络上的热梗。视频30秒
其实可以看到,它整体上并没有什么太大的问题,全流程是切切实实打通了的,视频很完整,还能选择生成60秒的视频。
但仔细看也会发现它的细节做得不到位。就比如说仙女是仿真人形象,她所处的环境是仿实景,但介绍天庭其他景点时就是动画风格。
不过这类似细节可以通过优化提示词调整。但要注意的是,提示词需要规避敏感词,有些现实中的景点名不太符合规定,比如我之前打算生成现实景点介绍视频,“李白故居”输入后提示不符合规定。
小猫经历霸凌和治愈
帮我制作一只小白猫在校被霸凌(被其他动物围着打,打得很暴力。周围同学表情凶狠),同学停止攻击后,小白猫艰难爬起来,而后哭着出校门到湖边,遇到正在钓鱼的胖金毛被治愈的视频。具体要求如下:
1.在校被霸凌内容大概占据五分之三,小白猫被胖金毛治愈内容大概占据五分之二。
2.胖金毛治愈的方式可以是带着小白猫一起吃烤鱼、给小白猫做毛球玩,当然也可以有其他方式。当然整个故事可发散。
3.视频出现的所有角色都是直立行走的拟人化动物。
4.整体视频每个镜头均采用3d写实卡通风格生成,保持生成画面中小白猫、胖金毛角色的一致性。
5.不需要旁白文案,但需要有环境(下课铃声、人多的嘈杂声音)、动作(打人的声音)、情绪音效(比如低声啜泣,比如不疼痛难忍)。还需要有小白猫和胖金毛的交流声音,小白猫通过不同语气的“喵喵”叫和动作体现,胖金毛通过不同语气的“汪汪”叫和动作表达体现。
这一次加大了难度,设置了一些剧情,提示词也更详细一些。
结果显示,“小云雀”能够从头到尾顺利流畅生成,只是无论我怎么强调“喵喵”叫和“汪汪”叫,它都给我上演了一场默剧。
还有2处细节明显有缺陷。第一个就是小猫在操场被围攻,只是被其他强壮的“同学”围了一圈,并没有生成正在被打的画面,就像虚张声势。若不是有小猫害怕的表情,我还以为是在一起跳舞呢!
第二个就是小猫哭着离校的路上,它的校服和前后不一致。
但这已经是我生成的几次中最好的一种结果了。在前几次生成过程中,它对情绪的理解更差。我倒是想省点时间在生成结果上继续修改,可它没有这个功能。
神仙医院里打妖怪
帮我制作24岁社畜苏小芊和太白金星、何仙姑在精神病院中打妖怪的剧情。具体要求如下:
1.剧情背景:部分神仙接到任务下凡搜集隐藏的大boss(魔头)信息,所以在这里修了一所医院(天庭驻人间办事处)。太白金星扮成精神病患者,在这里被称为“老白”,何仙姑扮演护士,在人类世界叫“林青荷”。人类25岁社畜苏小芊某天被雷劈了,机缘巧合成了阴阳眼,被当成精神病患者送到了这所医院,因此和太白金星、何仙姑相识并成了好朋友。
2.剧情细节补充:
精神病院。一天晚上,一个青面獠牙的妖怪正在心脑血管科翻病历,苏小芊经过过道第一个发现了这个妖怪。于是大叫,让后面的老白赶紧过来,让老白用打神鞭打妖怪,老白说拂尘上次被她逗猫玩坏了并掏出体温枪,正要开打时,林青荷护士从护士站冲出举起巨型针筒打妖怪,妖怪惊恐说自己只是来偷病历的。突然,一个声音从监控传来(这个只需要声音不需要露脸),警告青荷说,“青荷,说过多少次不准将法器化形成针筒。王母娘娘投诉你瑶池工作没交接好!”,趁大家分神之际,妖怪逃走了。
3.主人物介绍:有4个核心人物——苏小芊、老白(太白金星)、林青荷(何仙姑)、妖怪。老白和苏小芊穿着病服,青荷穿着护士服
4.整体视频每个镜头均采用CG动漫风格生成。保持生成画面中妖怪、苏小芊、老白、林青荷角色的一致性。
5.按照给定的剧情设计几个不同的数字人形象,全程不需要旁白,但是需要第一人称视角的台词。需要设计剧情对应的台词(监控对青荷警告的那句台词就用给定的,其他的根据剧情设计),在分镜内使用对应角色的数字人来演绎台词,做出短剧效果。
它不同的音色都挺贴脸,剧情就是要求的剧情。而且经过我的不断优化,同一角色形象不稳定、动画与真人画风混杂等问题也不存在了。但让适当拓展剧情的要求结果只是多了一句台词,每个分镜切得很快,就像放映ppt,分镜绝大多数都是单人镜头,最后一句台词的讲话人错了,应该是监控器里的声音。做这种短剧类的视频,毛病确实还不少。但我还是那句话,精准的提示词很重要,可能提示词到位了,整体效果也就到位了!照片说话-蒙娜丽莎唱歌
使用照片说话功能时,注意只能上传9:16尺寸的参考图,若不是这个尺寸会自动裁剪。
对于人物台词,你可以选择文本配音或者音频配音。其中文本配音只能输入80个字;音频配音可上传本地音频,也可选择样本音频,还可导入视频,不过音频和视频时长都需在15s之内(超出会自动剪辑为15s)。
这是它反馈的这个任务的结果:
我觉得还挺不错的,就很有喜感,还有特写,对嘴型挺ok。不知道其他内容视频如何。
照片说话-韩立直播带货仙丹
这次加了古风修仙背景,问题就暴露出来了。
这还是我认识的那个表情不多、仪态端方、谨慎小心、能苟就苟的韩老魔吗?
这夸张的动作和嘴巴开合度,完全脱离了人物形象本身。
主要还是平台没有精细化的设置选项,比如直播带货风格、场景设置等,也不能输入提示词。估计带货模板直接使用抖音电商直播带货的那套。
但若不设定古风背景,而是设定现代真实场景,可能效果就会好很多。
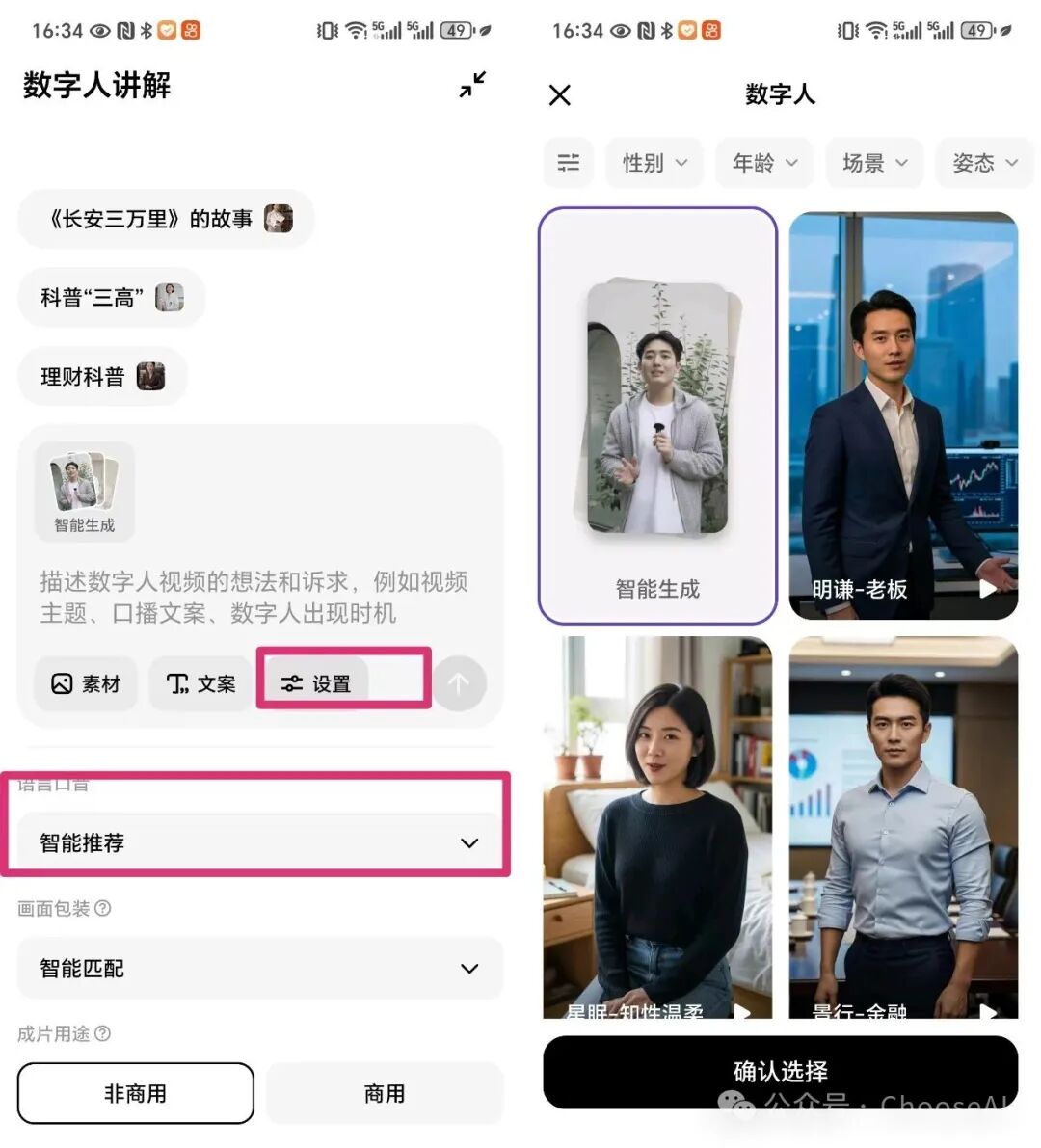
数字人讲解-青铜面具介绍三星堆
这个功能可以选择它给定的数字人形象,也可以直接让它根据提示词和文案内容智能生成数字人形象。除了常见的设置选项,这里还可以设置地域方言。
这是它给我反馈的结果:
提示词:
做一个三星堆青铜纵目面具介绍三星堆的视频,具体要求如下:
1.青铜纵目面具(参考附件)用固定文案(请见文案处填写的内容)为观众介绍三星堆和自己
2.视频40-60秒
3.第一人称视角,配音整体是沧桑幽默之感,要表现出青铜面具作为当事人的喜怒哀乐(骄傲、感慨、调皮、笑等情绪根据台词变化而变化),表现出它是性情中人,要分析文案讲述的情绪,对应的语句有对应的语气与感情。
4.自动配bgm,甚至可以加音效.
用这个文案作为台词
“(第一人称视角,青铜面具“活”了过来,语气带着沧桑与幽默)
“嘿,各位!我是三星堆的‘顶流’——青铜纵目面具,出土即热搜,三千年老网红了!”
(镜头拉远,展现三星堆遗址)
“我的老家,三星堆,位于四川广汉,是古蜀国的神秘都城。大约3000多年前,这里可是‘青铜文明’的天花板!没有文字记载?没关系,我们的青铜器自己会说话!”
(镜头聚焦面具细节,语气时而骄傲,时而感慨)
“看我这凸出的眼睛、夸张的耳朵,有人说我是‘外星人同款’,其实嘛……(叹气)我只是古蜀人眼里‘通天彻地’的神灵象征。祭祀时,他们对着我跳舞、祈祷,而我,就静静看着王朝兴衰……”
(语气突然调皮)
“后来嘛,商周战乱,我被埋进黄土,一睡就是几千年。直到1986年,考古学家一铲子把我挖出来——好家伙,直接震惊世界!现在,我可是博物馆的‘镇馆之宝’,每天被无数人围观打卡,比爱豆还忙!”
(最后深沉一笑)
“三千年岁月,我见证过古蜀的辉煌,也经历过沉寂。如今,我的故事仍在继续……(突然玩梗)下次来看我,记得带点‘电子香火’——拍照别开闪光灯啊!””
因为是数字人讲解,所以非人的物品都会长手长脚、以人样作为讲解者。这里直接用青铜人面覆盖了原本游客的脸,看起来比较滑稽。
但忽略这个,可以发现图随文动,台词和画面都能对应,还有现实的博物馆游览场景,挺形象生动了!
AI图片设计
这个生图功能和其他生图平台一样,可以文生图,也可以图生图,都是一次性生成4张。
先讲文生图。
它能理解中国历史文化。在图上生成文字也不会乱码。就文生图这个功能,它的效果和即梦相差无几。
比如:
(左为小云雀生成,右为即梦生成)
(左2张为小云雀生成,右2张为即梦生成)
“诸事顺利”提示词:
主体为以复古票据为原型,米黄底色,外围有繁复绿纹边框 猪八戒,手持钱包,往出冒金币,现代潮流服饰,球鞋,艳丽色彩,荧光油绘,夸张的线条,夸张的姿态,梦幻光影,水墨电影感。 中央用粗犷黑笔写着 '诸事顺利',顶部和底部有重复英文 'EVERYTHING GOES WELL',中间 'GOOD LUCK',两侧竖排英文 'LIFE IS SHORT WHY NOT TRY',周遭簇拥竖排小字,底部有英文 'Wish you all the heavenly blessings' 与红色篆刻印章的画面,国潮票据场景,复古花纹、书法狂草、篆刻印章与英文标语碰撞修饰,纸张边缘粗糙磨损,纸张纹理,红色印章突出清晰。而对于图生图功能,就不尽如人意。它加元素、变动作都能实现,只是如果主体是人,就可能会经历“一场场整容”。
比如它这里又改了韩立的形象:
(左为参考图,中为小云雀生成,右为即梦生成)
小云雀,赶紧把我们的韩老魔还回来!
换图片背景和风格
用“智能换背景”或者“AI图片设计”其实都能实现换图片背景,本质都是参考生图。
上传参考图后,输入主体所在的新背景即可。
(第1张为参考图,后2张为小云雀生成)
背景替换倒没翻车,还是之前提到的人物形象变化问题。
但风格问题就比较明显了,应该说,它底层模型上可能就没设置这个功能,可能就没有引入豆包的多种风格设置。
比如:(第一组让变成水墨画,第二组让变成吉卜力风格)
(左为参考图,右为小云雀生成)
一顿测试操作下来,乍一看,小云雀的细节不足之处还挺多。
但从整体性看,它将“内容策划-生成无声视频-配音-配字幕”等大大小小的步骤都缩减为一步,是大家肉眼可见很省事省时的agent。
这个直接重塑了目前视频创作的工作流程,标志着国内AI视频技术再上新台阶,让小白也能在10分钟内做出令人赞叹的创意视频!
至于细节,我相信过不了多久,它就能给我们满意的回复。
屏幕前的你有用过小云雀agent吗?有什么感想呢?欢迎在评论区留言一起讨论~
(我们的智能体已经上线了,可以在后台直接对话我们,就可以查工具教程或者测评)